Adversarial Learning for Good: My Talk at #34c3 on Deep Learning Blindspots
Posted on Do 28 Dezember 2017 in conferences
When I first was introduced to the idea of adversarial learning for security purposes by Clarence Chio's 2016 DEF CON talk and his related open-source library deep-pwning, I immediately started wondering about applications of the field to both make robust and well-tested models, but also as a preventative measure against predatory machine learning practices in the field.
After reading more literature and utilizing several other open-source libraries, I realized most examples and research focused around malicious uses, such as sending spam or malware without detection, or crashing self-driving cars. Although I find this research interesting, I wanted to determine if adversarial learning could be used for "good".1
A brief primer on Adversarial Learning Basics
In case you haven't been following the explosion of adversarial learning in neural network research, papers and conferences, let's take a whirlwind tour of some concepts to get on the same page and provide further reading if you open up arXiv for fun on the weekend.
How Does It Work? What Does It Do?
Most neural networks optimize their weights and other variables via backpropagation and a loss function, such as Stochastic Gradient Descent (or SGD). Similarly to how we use the loss function to train our network, researchers found we can use this same method to find weak links in our network and adversarial examples that exploit them.
To get an intuition of what is happening when we apply adversarial learning, let's look at a graphic which can help us visualize both the learning and adversarial generation.
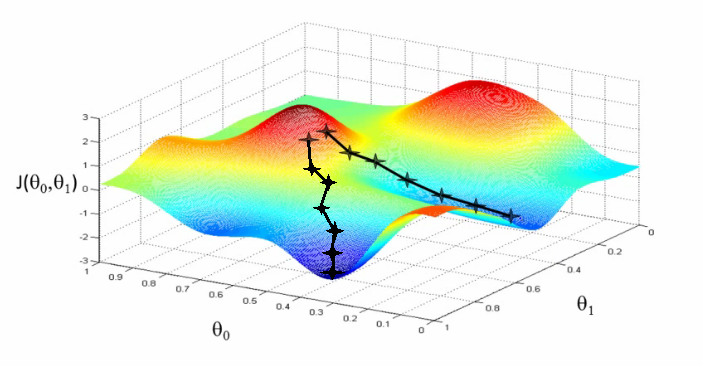
Here we see a visual example of SGD, where we start our weights randomly or perhaps with a specific distribution. Here our weight produces high error rates at the beginning, putting it in the red area, but we'd like to end up at the global minimum in the dark blue area. We may, however, as the graphic shows only end up in the local minimum of the slightly higher error rate on the right hand side.
With adversarial sample generation, we are essentially trying to push that point back up the hill. We can't change the weight, of course, but we can change the input. If we can get this unit to misfire, to essentially misclassify the input, and a few other units to do the same, we can end up misclassifying the input entirely. This is our goal when doing adversarial learning and we can achieve it by using a series of algorithms proven to help us create specific perturbations given the input to fool the network. As you may notice, we also need to have a trained model we can apply these algorithms to and also test our success rate.
Historical Tour of Papers / Moments in Adversarial ML
The first prominent paper on adversarial examples came in the form of a technique to modify spam mail to be classified as real mail, published by a group of researchers in 2005. The authors used a technique of addressing important features and changing them using Bayesian and linear classifiers.
In 2007, NIPS had their first workshop on Machine Learning in Adversarial Environments for Computer Security which covered many techniques related primarily to linear classification but also other topics of interest in security such as network intrusion and bot detection.
In 2013, following other interesting research on the topic Batista Biggio and several other researchers released a paper on Support Vector Machine (or SVM) poisoning attacks. The researchers were able to show they could alter specific training data and essentially render the model useless against targeted attacks (or at least hampered by the poor training). I highly recommend Biggio's later paper on pattern-based classifiers under attack and he has many other publications related to techniques to attack and prevent attacks on ML models.

Photo: Example poisoning attack on a biometric dataset
In 2014, Christian Szegedy, Ian Goodfellow and several other Google researchers released their paper Intriguing Properties of Neural Networks which outlined techniques to calculate carefully crafted perturbations of an image allowing an adversary to fool a neural network into misclassifying the image. Ian Goodfellow later released a paper outlining an adversarial technique called the Fast Gradient Sign Method or FGSM, one of the widely used and implemented forms of attacks on neural network classifiers.
In 2016, Nicolas Papernot and several other researchers released a new technique which utilized a Jacobian saliency map built using the Jacobian matrix of the loss function when given the input vector. He and Ian Goodfellow later released a Python open-source library called cleverhans which implements the FGSM and Jacobian Saliency Map Attacks (or JSMA).
There have been many other papers and talks related to this topic since 2014, too much to cover here, but I recommend perusing some of the recent papers from the field and investigating areas of interest for yourself.
Malicious Attacks
As mentioned previously, malicious attacks have been studied at length. Here are a few notable studies:
- Spam: Adversarial Machine Learning
- Malware recognition: Adversarial Examples for Malware Detection
- Malware generation: Generating Adversarial Malware Examples for Black-Box Attacks Based on GAN
- Poisoning of biometric data: Adversarial Biometric Recognition
- Attacks on self-driving cars: Robust Physical-World Attacks on Deep Learning Models
There are plenty more, but these give you an idea of what has been studied in the space. Of course, alongside many of these studies the authors studied counter-attacks. Security is ever a cat-mouse game so learning how to defend against these types of attacks, particularly with detection of an adversary or adversarial training is a research space in its own right.
Real-life Adversarial Examples
It has been debated whether adversarial learning will ever work for real-life objects or is just useful when the image is a static input such as an image or a file. In a recent paper, a group of researchers at MIT were able to print 3D objects which fooled a video-based Inception network into "thinking", for example, a turtle was a rifle. Their method utilized similar techniques to FGSM across a plane of possible alterations on the texture of the object itself.
How can I build my own adversarial samples?
Hopefully you are now interested in building some of your own adversarial samples. Maybe you are a machine learning practitioner looking to better defend your network, or perhaps you are just intrigued by the topic. Please do not use these techniques to mail spam or malware! Really though... don't.
Okay, ethical use covered, let's check out the basic steps you'll need to go through when building adversarial samples:
- Pick a problem / network type
- Figure out a target or idea. Do some research on what is used "in production" on those types of tasks.
- Research “state of the art” or publicly available pretrained models or build your own
- Read research papers in the space, watch talks from target company. Determine if you will build your own or use a pretrained model.
- (optional) Fine tune your model
- If using a pretrained model, take time to fine-tune it by retraining the last few layers.
- Use a library: cleverhans, FoolBox, DeepFool, deep-pwning
- Utilize one of many adversarial learning open-source tools to generate adversarial input.
- Test your adversarial samples on another (or your target) network
- Not all problems and models are as easy to fool. Test your best images on your local network and possibly one that hasn't seen the same training data. Then take the highest confidence fooling input and pass it to the target network.
Want to get started right away? Here are some neat tools and libraries available in the open-source world for generating different adversarial examples.
- cleverhans: Implementations of FGSM and JSMA in Tensorflow and Keras
- deep-pwning: Generative drivers with examples for Semantic CNN, MNIST and CIFAR-10
- FooxBox: Implementations of many algorithms with support for Tensorflow, Torch, Keras and MXNet
- DeepFool: Torch-based implementation of the paper DeepFool (less detectable FGSM)
- Evolving AI Lab: Fooling: Evolutionary network for generating images that humans don't recognize but networks do, implemented in Caffe
- Vanderbuilt's adlib: sci-kit learn based fooling and poisoning algorithms for simple ML models.
There are many more, but these seemed like a representative sample of what is available. Have a library you think should be included? Ping me or comment!
Benevolent Uses of Adversarial Samples (a proposal)
I see the potential for numerous benevolent applications of these same techniques. The first idea that came to mind for me was facial recognition for surveillance technology (or simply when you want to post a photo and not have it recognize you).
Face Recognition
To test the idea, I retrained the final layers of the Keras pre-trained Inception V3 model to determine if a photo is a cat or a human. It achieved 99% accuracy in testing.2 Then, I utilized the cleverhans library to calculate adversaries using FGSM. I tried varying levels of epsilon, uploading each to Facebook. At low levels of perturbations, Facebook immediately recognized my photo as my face and suggested I tag myself. When I reached .21 epsilon, Facebook stopped suggesting a tag (this was around 95% confidence from my network that the photo was of a cat).

[Photo: me as a cat]
The produced image clearly shows perturbations, but after speaking with a computer vision specialist, Irina Vidal Migallon3, it is possible Facebook is also using the Viola-Jones statistics-based face detection or some other statistical solution. If that is the case, it's unlikely we would be able to fool it using a neural network with no humanly visible perturbations. But it does show that we can use a neural network and adversarial learning techniques to fool face detection.4
Steganography
I had another idea while reading a great paper which covered using adversarial learning alongside evolutionary networks to generate images which are not recognizable by humans but are convincing to a neural network with 99% accuracy. My idea is to apply this same image generation as a form of steganography.

Photo: Generated Images from MNIST dataset which the model classifies with high confidence as digits
In a time where it seems data we used to consider private (messages to friends a family on your phone, emails to your coworkers, etc), can now be used to either sell you advertising or be inspected by border agents, I liked the idea of using an adversarial Generative Adversarial Network (or GAN) to send messages. All the recipient would need is access to training data and some information about the architecture. Of course, you could also send the model if you can secure the method you are sending it. Then the recipient could use a self-trained or pretrained model to decode your message.
Some other benevolent adversarial learning ideas
Some other ideas I thought would be interesting to try are:
- Adware “Fooling”
- Can you trick your adware classifiers into thinking you are a different demographic? Perhaps keeping predatory advertising contained...
- Poisoning Your Private Data
- Using poisoning attacks, can you obscure your data?
- Investigation of Black Box Deployed Models
- By testing adversarial samples, can we learn more about the structure, architecture and use of ML systems of services we use?
- ??? (Your Idea Here)
I am curious to hear others ideas on the topic, so please reach out if you can think of an ethical and benevolent application of adversarial learning!
A Call to Fellow European Residents
I chose to speak on the #34c3 Resiliency track because the goal of the track resonated with me. It asked for new techniques we can use in a not-always-so-great world we live in so that we can live closer to the life we might want (for ourselves and others).
For EU residents, the passage and upcoming implementation of the General Data Protection Regulation (or GDPR) means we will have more rights than most people in the world regarding how corporations use, store and mine our data. I suggest we use these rights actively and with a communal effort towards exposing poor data management and predatory practices.
In addition, adversarial techniques greatly benefit from more information. Knowing more about the system you are interacting with, knowing about possible features or model-types used will give you an advantage when crafting your adversarial examples.5 In GDPR, there is a section which has been often cited as a "Right to an Explanation." Although I have covered that this is much more likely to be enforced as a "Right to be Informed," I suggest we EU residents utilize this portion of the regulation to inquire about use of our data and automated decisions via machine learning at companies whose services we use. If you live in Europe and are concerned how a large company might be mining, using or selling your data, GDPR allows you more rights to determine if this is the case. Let's use GDPR to the fullest and share information gleaned from it with one another.
A few articles of late about GDPR caught my eye. Mainly (my fellow) Americans complaining about implementation hassles and choosing to opt-out. Despite the ignorant takes, I was heartened by several threads from other European residents pointing out the benefits of the regulation.
I would love to see GDPR lead to the growth of privacy-concerned ethical data management companies. I would love to even pay for a service if they promised to not sell my data. I want to live in a world where the "free market" system then allows for ME as a consumer to choose someone to manage my data who has similar ethical views on the use of computers and data.
If your startup, company or service offers these types of protections, please write me. I am excited to see the growth of this mindset, both in Europe and hopefully worldwide.
My Talk Slides & Video
If you are interested in checking out my slides, here they are!
Video:
Slide References (in order)
- Apple's Face ID tech can't tell two Chinese women apart
- Adversarial Learning (2005)
- NIPS Workshop: ML in Adversarial Environments for Computer Security
- Poisoning Attacks against Support Vector Machines
- Intriguing Properties of Neural Networks
- Stochastic Gradient Descent Image
- Synthesizing Robust Adversarial Examples
- Adversarial Manipulation of Deep Representations
- Practical BlackBox Attacks Against Machine Learning
- Transferability in Machine Learning: from Phenomena to Black-Box Attacks using Adversarial Samples
- cleverhans
- deep-pwning
- Vanderbilt Computational Economics Research Lab adlib
- DeepFool
- FoolBox
- Evolving AI: Fooling
- Evolving AI: Fooling - Deep neural networks are easily fooled: High confidence predictions for unrecognizable images
- GDPR: Recital 71
-
I am not a big fan of moral labels, so I use this term as it is widely understood. A much longer description of adversarial learning for ethical privacy-concerned motivations seemed like too long of a title and description, but that is my belief and intention. :) ↩
-
I think it's not a great implementation due to the fact that I don't work in computer vision and I used a few publicly available datasets with no extra alterations, but it did work for this purpose. If I was doing more than a proof of concept, I would likely spend time adding perturbations to the initial input (cropping, slicing), and find varied datasets. ↩
-
Irina's awesome PyData Berlin 2017 talk on deep learning for computer vision on a mobile phone is not to be missed! ↩
-
Facebook has recently released the ability to opt-out of suggested facial recognition. This was, however, more of a proof-of-concept than a "Facebook Fooling" experiment. ↩
-
However, this is not required. In fact, Nicolas Papernot has a series of great papers covering successful black box attacks which query the model to get training data and then create useful adversarial examples as well as transferability which shows you can use adversarial examples from one type of model to fool a different network or model with varying rates of success. ↩