Comparing scikit-learn Text Classifiers on a Fake News Dataset
Posted on Mo 28 August 2017 in research
Finding ways to determine fake news from real news is a challenge most Natural Language Processing folks I meet and chat with want to solve. There is significant difficulty in doing this properly and without penalizing real news sources.
I was discussing this problem with Miguel Martinez-Alvarez on my last visit to the SignalHQ offices; and his post on using AI to solve the fake news problem further elaborates on why this is no simple task.
I stumbled across a post which built a classifier for fake news with fairly high accuracy (and yay! the dataset was published!). I wanted to investigate whether I could replicate the results and if the classifier actually learned anything useful.
Preparing the data
In my initial investigation, I compared Multinomial Naive Bayes on a bag-of-words (CountVectorizer) features as well as on a Term Frequency-Inverse Document Frequency (TfIdfVectorizer) features. I also compared a Passive Aggressive linear classifier using the TF-IDF features. The resulting accuracy ranged from 83% to 93%. You can walk through my initial investigation published on the DataCamp blog to read my approach and thoughts (a Jupyter notebook of the code is also available on my GitHub). In summary, the data was messy and I was concerned the features were likely nonsensical.
Comparing different classification models
I wanted to take a deeper look into the features and compare them across classifiers. This time I added an additional few classifiers, so overall I would compare:
- Multinomial Naive Bayes with Count Vectors
- Multinomial Naive Bayes with Tf-Idf Vectors
- Passive Aggressive linear model with Tf-Idf Vectors
- SVC linear model with Tf-Idf Vectors
- SGD linear model with Tf-Idf Vectors
On accuracy without parameter tuning, here is a simple ROC curve comparison on the results:
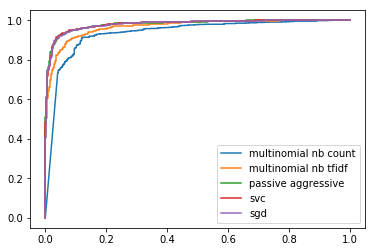 You can see that the linear models are outperforming the Naive Bayes classifiers, and that the accuracy scores are fairly good (even without parameter tuning).
You can see that the linear models are outperforming the Naive Bayes classifiers, and that the accuracy scores are fairly good (even without parameter tuning).
So indeed I could replicate the results, but what did the models actually learn? What features signified real versus fake news?
Introspecting significant features
To introspect the models, I used a method I first read about on StackOverflow showing how to extract coefficients for binary classification (and therefore show the most significant features for each class). After some extraction, I was able to compare the classifiers with one another. The full notebook for running these extractions is available on my GitHub. I will summarize some of the findings here.
Fake news has lots of noisy identifiers
For the most models, the top features for the fake news were almost exclusively noise. Below is the top ten features ranked by weight for the most performant Naive Bayes classifier:
| Feature | Weight |
|---|---|
| '0000' | -16.067750538483136 |
| '000035' | -16.067750538483136 |
| '0001' | -16.067750538483136 |
| '0001pt' | -16.067750538483136 |
| '000km' | -16.067750538483136 |
| '0011' | -16.067750538483136 |
| '006s' | -16.067750538483136 |
| '007' | -16.067750538483136 |
| '007s' | -16.067750538483136 |
| '008s' | -16.067750538483136 |
You might notice a pattern, yes? The "top features" all have the same weight and are alphabetical -- when I took a closer look there were more than 20,000 tokens as top performers with the same weight for Naive Bayes.2
The top linear model features for fake news looked like this:
| Feature | Weight |
|---|---|
| '2016' | -5.067099443402463 |
| 'october' | -4.2461599700216439 |
| 'hillary' | -4.0444719646755933 |
| 'share' | -3.1994347679575168 |
| 'article' | -2.9875364640619431 |
| 'november' | -2.872542653309075 |
| 'print' | -2.7039994399720166 |
| 'email' | -2.4671743850771906 |
| 'advertisement' | -2.3948473577644886 |
| 'oct' | -2.3773831096010531 |
Also very noisy, with words like "share" and probably "Print article" as well as date strings (likely from publication headers). The only token that is not from auxiliary text on the page is likely Hillary, which in and of itself does not classify fake from real news. 1
Linear Models agreed that "to say" is a real news feature
For the linear models, forms of the verb "to say" appeared near the top -- likely learning this from professional journalism quotations (i.e. Chancellor Angela Merkel said...). In fact, "said" was the most significant token for the top linear model, edging out the next token by 2 points. Here is a short summary of real news top tokens from the Passive Aggressive classifier:
| Feature | Weight |
|---|---|
| 'said' | 4.6936244574076511 |
| 'says' | 2.6841231322197814 |
| 'cruz' | 2.4882327232138084 |
| 'tuesday' | 2.4307699875323676 |
| 'friday' | 2.4004245195582929 |
| 'islamic' | 2.3792489975683924 |
| 'candidates' | 2.3458465918387894 |
| 'gop' | 2.3449946222238158 |
| 'conservative' | 2.3312074608602522 |
| 'marriage' | 2.3246779761740823 |
Although there are more real topics included, there is also words like Friday and Tuesday. Perhaps we should only read the news on Friday or Tuesday to ensure it is real...

Overall, the top tokens were mainly noise
When I aggregated the top tokens for both real and fake news, sorting by count (i.e. the most common tokens identified as real and fake for all models), I saw mainly noise. Here are the top tokens sorted by the number of occurrences for identifying real news:
| Aggregate Rank | Count | Label | |
|---|---|---|---|
| said | 9.8 | 5 | REAL |
| cruz | 3.5 | 4 | REAL |
| tuesday | 8.33333 | 3 | REAL |
| conservative | 4.66667 | 3 | REAL |
| gop | 3.33333 | 3 | REAL |
| islamic | 6.33333 | 3 | REAL |
| says | 8.33333 | 3 | REAL |
| president | 5.5 | 2 | REAL |
| trump | 9.5 | 2 | REAL |
| state | 3 | 2 | REAL |
And the top tokens for identifying fake news:
| Aggregate Rank | Count | Label | |
|---|---|---|---|
| 2016 | 1 | 3 | FAKE |
| share | 5 | 3 | FAKE |
| 7.33333 | 3 | FAKE | |
| october | 2.66667 | 3 | FAKE |
| november | 5.66667 | 3 | FAKE |
| hillary | 2.33333 | 3 | FAKE |
| article | 4.33333 | 3 | FAKE |
| 0000 | 1 | 2 | FAKE |
| election | 7.5 | 2 | FAKE |
| 000035 | 2 | 2 | FAKE |
To see the code used to generate these rankings, please take a look at the Jupyter Notebook.
Takeaways
As I conjectured from the start, fake news is a much harder problem than simply throwing some simple NLP vectors and solving with linear or Bayesian model. Although I found it interesting that the linear classifiers noticed real news used quoting verbs more often, this was far from a deep insight that can help us in building a real vs. fake news filter which might improve democracy.
I did have fun spending a short time building on a few ideas and found it useful that the linear models performed better in terms of token noise for real news. If I had taken time to clean the dataset of these tokens, I'm curious how the comparison between the models would change.
In the end, the dataset is likely not a great candidate for building a robust fake versus real news model. It seems to have a lot of token noise (dates, share and print links and a limited variety of topics). It is also fairly small and therefore any models would likely suffer from having a smaller token set and have trouble generalizing.
I'm always curious to hear other trends or ideas you have in approaching these topics. Feel free to comment below or reach out via Twitter (@kjam).
Footnotes
-
Perhaps the fact that Clinton did not appear alongside it might mean a longer n-gram could identify references to popular alt-right and conservative monikers like "Lying Hillary" versus "Hillary Clinton"). ↩
-
Some fun ones in there included '11truther', '0h4at2yetra17uxetni02ls2jeg0mty45jrcu7mrzsrpcbq464i', 'nostrums', 'wordpress' and 'woot'. (I'm sure there are many more finds awaiting more study ...) ↩