Private and Personalized AI
Posted on Di 19 November 2024 in personal-ai
I recently had the wonderful experience of keynoting PyData Paris, thanks again for the invite! When deciding on a topic, I was considering my recent research about how AI/ML systems memorize data. As I've mentioned in a few talks, if we indeed embraced the fact that machine learning systems memorize training data, we'd probably design them differently. What would it look like if you could just use your own data, or own your own model, or both?
I've been inspired by recent AI product shifts in this direction including the Apple Intelligence launch, which promises to be more private and personalized. Although it's not available yet in the EU, likely due to its currently closed functionality, I am excited to see what innovation it brings to thinking about personalization in AI/ML systems.
These developments struck me as similar to other events in technology history, like the emergence of the personal computer. Maybe we can learn from that history to see how to make AI systems a helpful and integral part of our society?
What can we learn from history?
At present AI is a centralized, specialized field. It reminds me a lot of early computing or pre-cloud data centers. Early computers were huge machines in rooms full of specialists, used only for special tasks. Here is an example of such a machine and its engineers in the late 1950s.
 An IBM 704 mainframe at NACA in 1957
An IBM 704 mainframe at NACA in 1957
The parallels are actually quite striking when you list out some characteristics:
- large, expensive and centralized compute
- run by a small group of highly specialized workers
- task-specific programming, often for research or large corporate interests
What brought about the revolution in computing? What made it so that we all walk around with a computer in our purse, pocket, bag?
One of the initial turning points was the development of the personal computer (PC), but even that was mainly used by hobbyists and didn't initially have wider market impact. But as software became more useful, that perspective shifted. One good example of this shift was VisiCalc on Apple II.
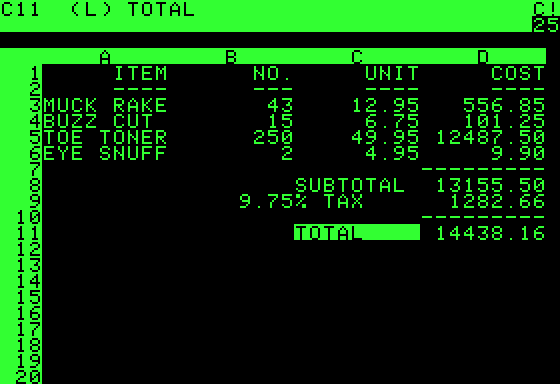 VisiCalc
VisiCalc
With VisiCalc, people could finally see something really useful, something that was worth buying a fairly expensive piece of electronics to do. Everyone needs spreadsheets, right?
This success started a growing trend of making software not just for hobbyists, but for the general public, for your work and life. This momentum created more focus on user-friendly, understandable GUIs (graphic interfaces), it let people bring their own data and it created experiences of joy and fun. As this trend continued, there was a need to use more than one computer, or connect with others -- building both the market and actual demand for the internet and things like web browsers. Each of these steps in computing development brought new use cases, new persons, new data and new communities along with them.
Is AI community-oriented? User-friendly? Easy?
This brings us back to the current status in AI. Where are we in this evolution?
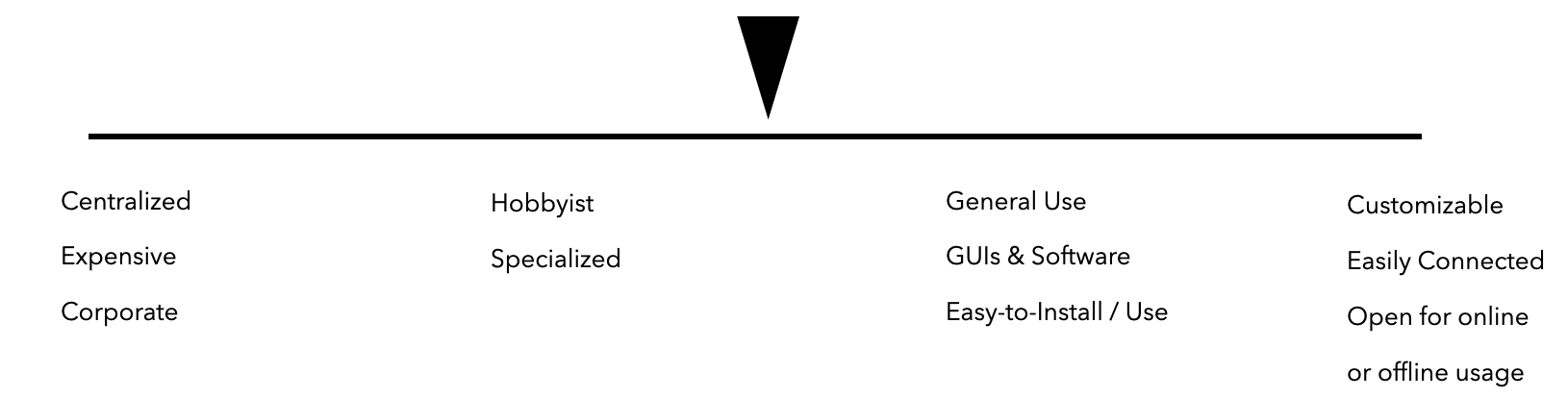 Where do you place AI systems on this scale?1
Where do you place AI systems on this scale?1
I think we are still somewhere in these early stages of VisiCalc, approaching the next stages, but somewhat slowly due to the lack of truly open models with open data. It's still quite difficult to try to bring your own data or your own use case -- other than typing something into a prompt or uploading one image at a time in an interface.
How do I easily connect AI to the documents on my computer? How do I use it with my photo storage or art? How do I have it only use my writing, documents, emails?2 Can I train it myself to get the results I want (i.e. by labeling myself and/or engineering my own prompts without having to learn much about how it works)? How do I do all of this safely and successfully (i.e. without having to reread everything and do everything twice)?
One of the main problems in achieving the next stages is that popular AI systems are inherently intransparent. This is a great marketing trick because you can claim magic, but awful for actually making AI systems more trustworthy and useful for humans. As a user, I don't have to understand everything, but I should be able to understand enough to avoid poor quality outcomes. I should also trust things enough to know they won't accidentally reply to an email from my boss with details about my upcoming job interview or provide a profile photo with my underwear showing. :/
What will be the pivotal point that takes AI (or agents or ML models) from where we stand today and moves them into a true revolution, where everyone uses the AI systems directly as regularly as they open their laptop or unlock their phone?
Imagining what is possible: Local Document Search, Retrieval and Chat
I think this will come first when you can run an AI system as easily as installing software or an application on your phone. It needs to work offline or you need to control when and how it connects and what data it sends (because of the aforementioned trust issues and general usefulness).
To test out what I wanted in relation to personalized AI, I built a completely local RAG. I'd already downloaded and tried Ollama and GPT4All, both which I liked, but I couldn't tinker with them as easily as I expected and I wanted to build out some other features I had in mind... (more on this soon!)
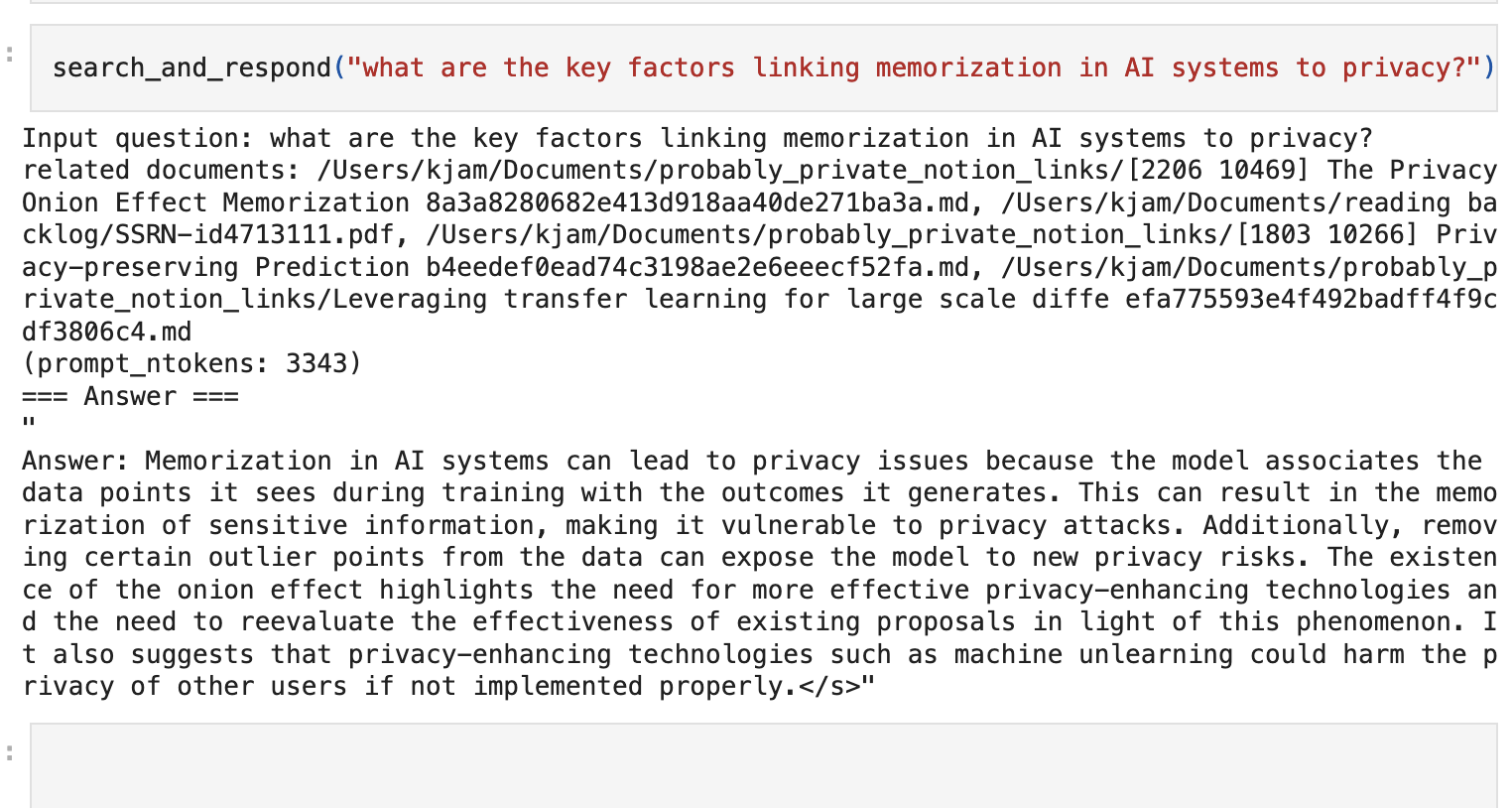 A local, offline RAG system search and response
A local, offline RAG system search and response
I built mine using examples from UKPLab's sentence transformers and Mozilla's Llamafiles. I didn't need a bunch of add-on libraries and it was quite straightforward. I went for simplicity and ability to shift out models or search easily over robustness and functionality. I also wanted it simple so that I could easily demonstrate how the underlying systems work (transparency is important!).3
I released my proof-of-concept as a Jupyter Notebook on GitHub](https://github.com/kjam/personalized-ai) with annotations. I'll be adding more notebooks, command-line programs and functionality to this -- so if you'd like to contribute, let me know!
I'll also be releasing other personal-AI/ML model examples and workflows in the coming weeks and months to inspire others, debunk mythology about how "hard" it is to build local-first data and AI and to hear your feedback on what's interesting and useful.
I believe we're at a critical moment in the adoption of AI and ML systems as something that can help connect us, that can serve real purpose and that can also be reliable, trustworthy and interesting (maybe even fun!). There's also some pretty dystopian futures that could occur if we continue to have intransparent, corporate-driven AI systems that are more smoke and mirrors than science. I'd like us to use this moment to build AI futures we actually want to see.
-
I'd be curious to hear your thoughts, so feel free to write me an email or reach out on LinkedIn. ↩
-
Some people say this is achieved by AI Agents, but I have yet to see an agentic workflow that is clear, trustworthy and transparent enough that I would install it and use it on my computer. I think the security and privacy problems with agents will continue to grow in the short-term, and that they will likely only be fixed with actual user control and transparency--including local-first model design and deployment. ↩
-
I took inspiration from Ben Clavié's talk on RAG system design, where he recommends splitting search and retrieval from summarization. I concur that this gives much better results. Thank you for your work! ↩