Machine Learning dataset distributions, history, and biases
Posted on Mi 13 November 2024 in ml-memorization
You probably are already aware that many machine learning datasets come from scraped internet data. Maybe you received the infamous GPT response: "Please note that my knowledge is limited to information available up until September 2021." You might have also read fear-mongering opinions and articles that companies will "run out of data" to train AI systems soon.
In this article, you'll examine exactly how data is collected. You'll look at what properties this data has and evaluate known issues with such collection processes, such as amplifying systemic biases and obscuring privacy. Understanding these points will help you better understand machine learning memorization and evaluate deep learning when designing systems. In this article and the next few articles, you'll be focusing on understanding how machine learning systems work, so that you can later understand how they memorize.
| TLDR (too long; didn't read) |
|---|
| Datasets collected online have a long-tail distribution |
| Common examples are heavily repeated |
| Uncommon examples outnumber common examples |
| Trying to learn uncommon examples in ML systems is hard |
| Data collection culture is grab everything as cheaply as possible |
| The history of the internet and internet culture introduce systemic biases |
| This creates problems with privacy, equity and justice in ML systems |
Watch a video summary of this post
Let's explore today's collected datasets and see what you can learn about them and how they work. In this series, you'll focus specifically on data collected for large-scale deep learning tasks.
Natural Datasets of Scraped Text and Images
When you collect a large sample of text or image data and visualize the distribution, you often see a long tail. This was described by linguist George Zipf, and is sometimes referred to as the Zipf-distribution or Zipf's law. With a long tail or Zipf probability distribution, you have more common types of examples and a long set of examples that are far less common.
The probability distribution of the long tail looks like this:
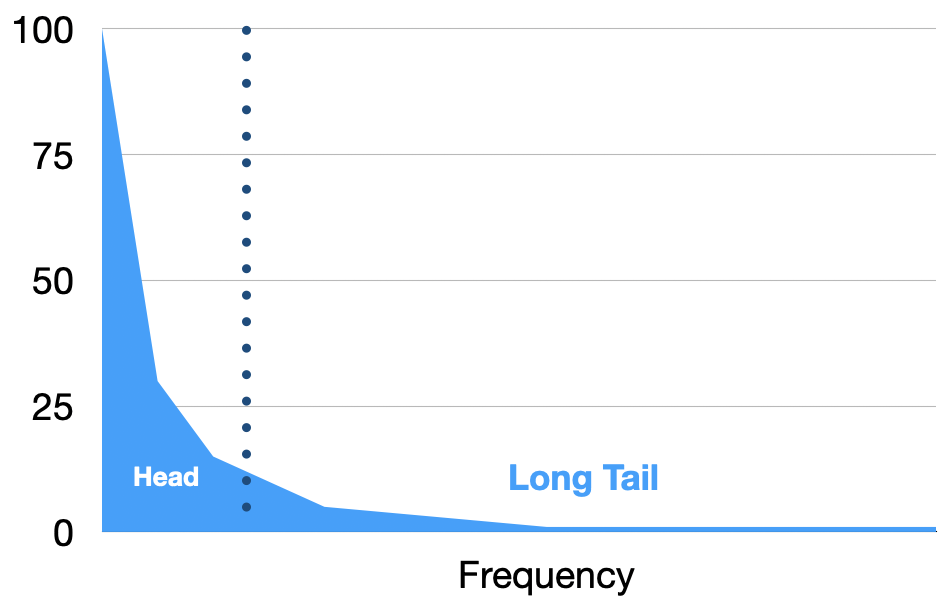
The common examples in the "head" occur at a much greater frequency than the less common "tail" examples. In addition, the tail composes a significant part of the entire distribution, so if you want to learn how to differentiate the examples in the tail (as with machine learning), this presents a difficult problem. How do you know what parts of the tail you need to learn and what might be not worth learning? Should you learn all of it, even examples which are singletons (i.e. only one example) or which may be outliers or errors?
Because of the difficulty, there is significant research dedicated to studying the Zipf or so-called "long tail" distribution. A survey of deep learning with the long tail explored a variety of approaches to address the long tail problem, including oversampling1 of the less common occurrences to ensure the model appropriately learns these classes and examples.
Another piece of research found two long tail problems in computer vision datasets. The first long tail happens when looking at the distribution of data across the classes2 or labels, like "person" or "bus" or "Ziggurat". In this distribution images of common objects and classes compose the head and much less common objects are in the tail.
Within a class there is also a long tail based on other attributes. As shown in the following graphic, the positioning of the object in the photo has its own long tail distribution within a particular data class. The visual aspects of the objects within a class--for example, all photos labeled as buses--have typical representations for buses where the bus is in the center of the photo without any visual impediments or any other vehicles in the photo. There are also atypical views, where just the top part of the bus is visible over other cars and vehicles.
These less common images are part of the tail of the class "bus", which is already in the tail of the overall categories of images collected. This makes a complex problem even more complex!
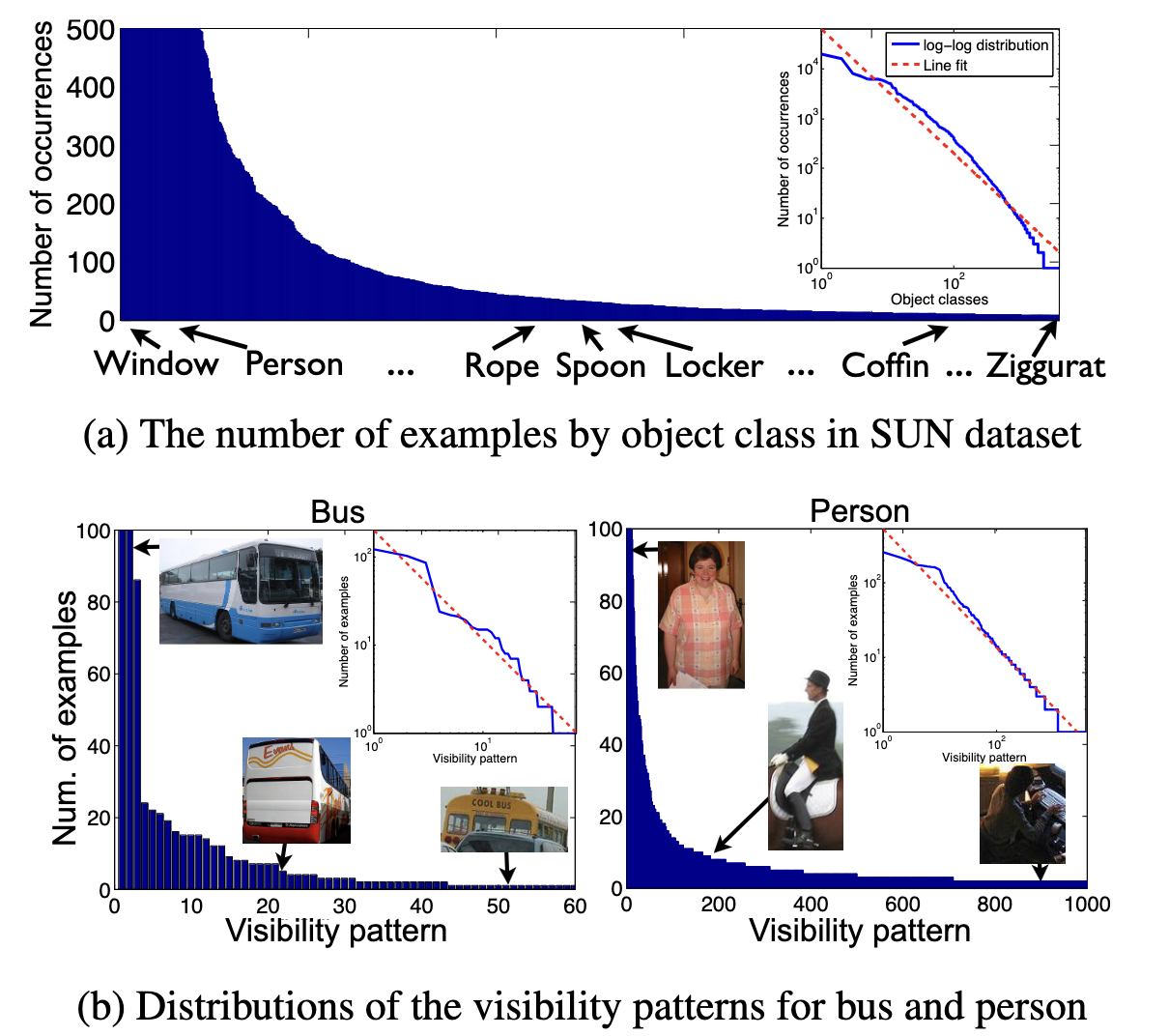 Long tail of all classes and long tail within a class
Long tail of all classes and long tail within a class
When these datasets are scraped at scale, the head represents larger classes, like photos labeled as persons or prominent buildings or text related to a common topic in a common language, like US-centric English-language news. Within those overrepresented classes, there are also less common examples of that population or class, like local news events which don't make US national news or a photo of a building that doesn't exist anymore.
What about the entirety of the tail, though? In natural language processing, this means ALL of world languages end up being a much smaller representation when compared with available text in English, due to the use of English on the internet.3 Within computer vision, generation of typical "wedding" images look like US weddings because the much higher occurrence of those photos online greatly outweigh other representations of weddings around the world.
This point will be quite important for understanding how memorization happens. To give you a preview, I want you to try to draw a "generic" person or make a list of what you might use to decide if a photo has a person in it. Would your list work for all photos you can take of a person or of people? What list would you need in order to make sure that all photos of people are classified correctly?
Online spaces create a fair amount of content duplication, especially since the advent of the search engine and search engine optimization. Photos of people in front of the Eiffel Tower are much more common than animals in their natural habitat or life in places with fewer digital cameras and devices. For text, there exist massive duplication of boilerplate letter text, common licenses (like the Apache license), common marketing content, content with large distribution channels (like AP news blurbs) and even famous quotes. These texts are usually in English and represent US spelling and grammar rules.
If you try to learn the entirety of the world, which might be the case if your goal is to create a "general AI" system, the duplicates make learning more difficult, because they are overrepresented. Finding duplicates to remove is easy if the duplicates are an exact match. But usually you have to solve the problem of near-duplication, where data is very close but not actually exactly duplicated. This is still a hard problem to automate.
Humans are good at noticing things like if a photo is from the same moment or photoshoot but from a different angle. Humans are also good at noticing things like plagiarism or when an idea, quote, or section of content is mimicking another piece of content. Computers are still not very good at this. Therefore, it's unlikely you can truly remove all duplicates that a human might mark as duplicate using computer-assisted methods. Large deep learning models often memorize repeated data, which you'll explore later in this article series.
But, just how did scraped internet data come to represent "the world"? If the data was more diverse, would the resulting models be more representative? Would the models learn fewer biases? Let's explore by examining the history of machine learning data collection.
Data Collection for Machine Learning: A History
In the early days of deep learning, many datasets were collected by researchers or university research groups to provide data for deep learning research.
One famous dataset is the MNIST dataset, first introduced in 1998 by Yann LeCun et al. The dataset is a canonical example for any computer vision student or machine learning hobbyist.
The original dataset was collected by US National Institute of Standards and Technology (NIST) employees, who were asked to fill out a form that collected their writing. Then the dataset was expanded because it was too small and not as diverse as real handwriting, so the researchers asked several US high schools to participate. The students filled out forms that looked like this:
 NIST Handwriting Form
NIST Handwriting Form
The details on how this assignment was given and if consent was collected are fuzzy, but as an 80s child from the US, this paper looks like a classroom assignment, not an activity kids would fill out for fun in their own time. There is no information on the form about what the data will be used for which makes it hard to understand if, when and for how long the information from the form will be saved. Of course, these letters and digits have now been duplicated across the world many times for every entry-level computer vision class. If a student wanted to revoke consent for machine learning, this would now be impossible.
This initial start turned into a longer trend, best described as "collect data as cheaply and as quickly as possible". This trend became a widespread fundamental practice within the field of machine learning. For those that did it well, it was also immensely profitable.
Indexing the internet and all of its content fueled the growth of today's large scale technology companies like Google who advanced the organization's search engine capabilities via massive data collection. These datasets were collected without special attention to copyright, privacy or consent, other than avoiding websites that specifically blocked crawlers via the 'robots.txt' file.
The data collection was described as "indexing", where keywords were matched to content URLs. But to produce these matches, the entire website content was scraped and saved first. The scraped data--usually a file or set of files--could be deleted or updated by contacting Google if you were the person running the website, which may or may not be the person whose content was posted.
Additional datasets like Flickr30K and Labeled Faces in the Wild show a similar approach to data collection within the computer vision domain -- grab whatever you can and ask questions (or for permission) later.
Unfortunately, this isn't exactly how many of us use the internet or at least not until recently. Helen Nissenbaum speaks about the context in which you write, post photos and connect with others online, and how this context often doesn't match the mental model you have when operating in the real, non-digital world. It's difficult for humans to understand exactly how, where and to whom they are sharing information with via a digital interface because the context and related transparency on how the data is used, stored and managed isn't entirely clear.
When you are writing to a close friend by commenting on their post, you probably don't immediately assume a complete stranger will read it or scrape it and use it for machine learning. When you posted something 10 years ago on a personal blog, you probably didn't assume it would be stored somewhere a decade later and used in the latest GPT model. When you shared your photos on Flickr in 2010, you didn't foresee that it could end up in a Generative AI portrait. And yet, those things are indeed possible due to the lack of contextual integrity provided in many online spaces and platforms.
Training with online data has other pitfalls and challenges, many to do with the skewed culture of the internet itself and the resulting biases in these scraped datasets.
Internet Culture and Biases
The internet was initially used by a small group of people, available only in a small number of places. It still carries the biases of those groups--being a place where it's often safer to be "Western", white and male.
These online biases show up in training datasets produced by scraping the web. For example, one large NLP dataset used to train early GPT models was The Pile. The Pile encompasses several scraped datasets, including one called OpenWebText2. This dataset contains the text of all the websites with top-rated linked Reddit posts between 2005 and 2020. Not only is this dataset a violation of those users' belief they could later delete their posts, but Reddit also hosts several popular communities promoting visceral and violent hatred, racism and bigotry.
The resulting datasets show massive societal biases, including, but not limited to racism, sexism, homophobia, US-centrism and xenophobia. Work from researchers like Timnit Gebru and the DAIR Institute, danah boyd and Kate Crawford have highlighted these biases since 2017. Research like Calisken et al.'s analysis of sexism in translation, Bolukbasi et al.'s work, whose article borrows from my initial research about sexism in word vectors, have been available since 2016. Buolamwini and Gebru's Gender Shades demonstrated in 2018 that darker skinned women are at a disadvantage when it comes to accurate facial recognition. These problems are well documented for nearly a decade and yet the common practice in machine learning communities is to still use these problematic datasets and to produce more by scraping more data.
Although text data can be used directly as it is collected, image data must be appropriately labeled to perform adequate computer vision or text-to-image generative tasks. For text-to-image or image-to-text models, the labels involve either describing the entire image or scene, or creating bounding boxes, where parts of the image are highlighted and describing a smaller subsection of the image. This might involve labeling all objects in the image separately along with their bounding boxes.
For early computer vision datasets, appropriately learning labels (or categories of things, like a "cat") meant data collection attempted to find images with only one thing in them. To learn more quickly and to have more data with the same labels, this might mean that a photo of a person is just labeled "person", and that image may be of the person in the center, in the side, or in some other part of the image. As you can imagine, these labels vary significantly in quality and accuracy, depending on how they are collected. Many of today's labels are semi-automatically scraped from the web and use image ALT text as the description.5
For higher-quality datasets, humans work as labelers of scraped or user-generated text, images and videos. These data workers are frequently subjected to poor working conditions and lack of psychological support when facing traumatic content for systems like content moderation. For other machine learning tasks, the instructions are often meager and very little context is given to the data workers, resulting in datasets with lower quality assurance than one would want if people were properly informed about the task.6
Crawford and Paglen highlight additional issues with crowd-sourced labels in Excavating AI. Their research and the resulting art piece and essay investigated the ImageNet dataset--highlighting labels like "alcoholic", "ballbuster" and "pervert". There is extensive academic research on the topic, like how online images amplify gender biases and other systems of oppression explored in Flickr 30K dataset research.
Even without human labelers, collected data from the internet reinforces biases and stereotypes from search algorithms and content providers. Safiya Noble documented biases in search engines and their results in Algorithms of Oppression. Her book inspired me to look at what surfaces in popular web crawl datasets, uncovering what it's like, for example, to search for "Brazilian Girl" in the C4 dataset (a part of the common crawl).

The initial examples from the first two pages of results talk about how to ask a Brazilian girl out, how to date a Brazilian girl or they are fake advertisements to meet Brazilian girls. When this data is the only context a large language model or generative model receives on what "Brazilian girl" represents, then in the resulting model "dating" is closer to that idea than being a scientist, researcher, politician, athlete, philosopher, etc.
These internet biases create AI systems that repeat and expand their use and can influence people are seen by others and how people see themselves. This has lasting impacts on society, and creates an amplification and further entrenchment of harmful content.
It's important to keep this in mind when learning about machine learning. What data are you trying to learn? What data do you think is "high quality" and why? What is the machine learning community doing by attempting to build expansive, cheap datasets?
And when memorization happens on these data, what is memorized and reproduced from this internet culture?
Bigger question: what even is data?
Often these datasets are representing only a subset of the world, as you've learned thus far. Why are they used as universal truths if they can only represent a small sample of reality?
danah boyd wrote about how measurement and scientific inquiry come from murky histories of cultural dominance, colonization and oppression. By assuming that there is a standard system of measurement for everything, the assumptions and biases built into what is "normal" and who determines these standards leave some examples marked as "normal" and others marked as outside. Since machine learning then uses these standards and measurements to automatically learn to discriminate from one group, idea or concept to another, these biases are highlighted, reproduced and become entrenched in the concept of data.
Understanding memorization begins with understanding how data is collected and used, and what properties that data has. Massive duplication and the long-tail have a deep impact on how machine learning models--particularly deep learning models--learn, generalize and memorize.
The ethical, social and philosophical problems of how data is collected and labeled are also important to study alongside memorization because it is very difficult to unlearn these concepts. When memorization of these biases happen, it creates an even more difficult problem to attempt to stop reproducing those examples, often creating a need for serious intervention or complete redesign and retraining.
In the next article, you'll investigate how machine learning systems take these datasets as input and process them for machine learning. Specifically, you'll investigate how encoding and embeddings work to take complex input and make it easy to "learn".
I'm very open to feedback (positive, neutral or critical), questions (there are no stupid questions!) and creative re-use of this content. If you have any of those, please share it with me! This helps keep me inspired and writing. :)
-
Oversampling involves pulling from a certain subset of examples more frequently when performing a machine learning or analysis task in order to ensure they are better represented within the overall dataset or population. This is a basic statistics strategy which help when using nonrepresentative data or when minority subpopulations need to be adequately evaluated (i.e. when one or more groups are heavily overrepresented compared to other groups). If performed, the resulting data analysis or machine learning is much more likely to process duplicates from the oversampled population. This becomes an important factor for memorization, which you will explore in a later article. ↩
-
Categories like "bus" or "person" are referred to as classes. Photos are labeled in order to be able to see an image later and create a prediction on what is in the image (like a bus). A dataset that is to be used for a classification problem might refer to classes as labels (or vice versa), because the data is tagged or labeled with the class name or encoding (sometimes a number that maps to a human-readable name). Technically, the classes refer to the categories. When the dataset is collected and the examples are tagged with the appropriate matching class, that process produces a label. ↩
-
This has prompted significant research and deployment strategies to offer better multi-lingual AI products, including joint research from Microsoft China and university researchers which first translates incoming text and prompts into English to use a production LLM system which performs much better at English text than Chinese. ↩
-
The early internet was available to researchers and government and military personnel. As the World Wide Web grew, it was most accessible in the US and parts of Europe, where internet access for non-academic and non-military persons was subsidized and supported by local authorities. This created an overrepresentation on the web of these world views and lifestyles. The early internet boom and resulting web infrastructure was primarily located in Silicon Valley, California, which brought the area and users' own political, economic and social views to the newsletters, websites, browsers and search engines of the time. These marks are still recognizable in the way many people search, browse and experience the internet today. ↩
-
Due to the internet's propensity to skew representation, this practice results in a Western, white supremacist and patriarchal view of personhood. Ghosh et al demonstrated that Stable Diffusion models prompted with "person" overwhelmingly produce a white male. Their research also uncovered erasure of indigenous identities and hypersexualization of women from particular areas of the world. ↩
-
The lack of instructions and connection to the larger team and task could be a result of trying to keep the data workers (often subcontractors working for another company) further removed from their peers working on other parts of machine learning, like the high-paid data workers who train the models or architect the resulting systems. ↩