Differential Privacy in Deep Learning
Posted on Mo 10 November 2025 in ml-memorization
Differential privacy influenced both privacy attacks and defenses you've investigated in this series on AI/ML memorization. You might be wondering: what exactly is differential privacy when it's applied to deep learning? And can it address the problem of memorization?
Are you a visual learner? There's a YouTube video on this article on the Probably Private YouTube channel.
In this article, you'll learn how differential privacy is applied to today's AI/deep learning models and evaluate if this could be a useful approach for addressing memorization problems. In following articles, you'll explore limitations of applying differential privacy in today's systems and critically think through auditing real-world applications.
What is differential privacy in machine learning?
My favorite definition of differential privacy comes from Desfontaines and Pejó's 2022 paper (brackets are added for this particular scenario):
An attacker with perfect background knowledge (B) and unbounded computation power (C) is unable (R) to distinguish (F) anything about an individual (N) [when querying a machine learning model], uniformly across users (V) [whose data was in the training dataset] even in the worst-case scenario (Q)
That seems like a pretty high bar compared to what you've been evaluating with unlearning! Differential privacy offers a fairly strict and rigorous definition of privacy standards. For that reason it's often used with combinations of the variables (shown in letters above) to determine if a stronger or weaker definition should be used based on use-case or context-specific privacy requirements.
Differential privacy provides guarantees for every individual when applied to data collection, access and use, while still offering enough information to learn something. This is the balance between data utility and individual privacy.
TIP
If you're new to differential privacy, I highly recommend taking a gander through Damien Desfontaines's introduction and in-depth articles. You can thank me later. :)
Ideally when doing machine learning, you are learning from many persons not from one individual; therefore, differential privacy is a natural fit if you want to make sure that you learn from a group and not from any one specific person.
But, as you've learned throughout this series, this can be challenging when novel, complex examples show up...
Can differential privacy help with memorization and privacy attacks?
You might recall from the previous article on differential privacy that differentially private models reveal memorization problems in deep learning. Differentially private models underperformed on particular novel examples when compared with their non-differentially-private counterparts.
Indeed, this is often the case. In research from Stock et al (2022), models trained using differential privacy were successful in defending against reconstruction attacks. Models trained using differential privacy protected the training data better than non-DP models. In this research, the authors found that although some membership inference attacks succeeded, they were unable to extract and reconstruct the training data based on the differentially private model responses, even when the MIA was successful.
To test this, they inserted canaries into the dataset and specifically targeted these canaries. They found that a model without differential privacy memorized the canaries and they were easy to reconstruct using normal exfiltration attacks. The DP model, even one with fairly weak definitions, revealed only that it had seen the canary via a successful model inference attack, but without the canary example in hand, an attacker could not extract the canary from the model.
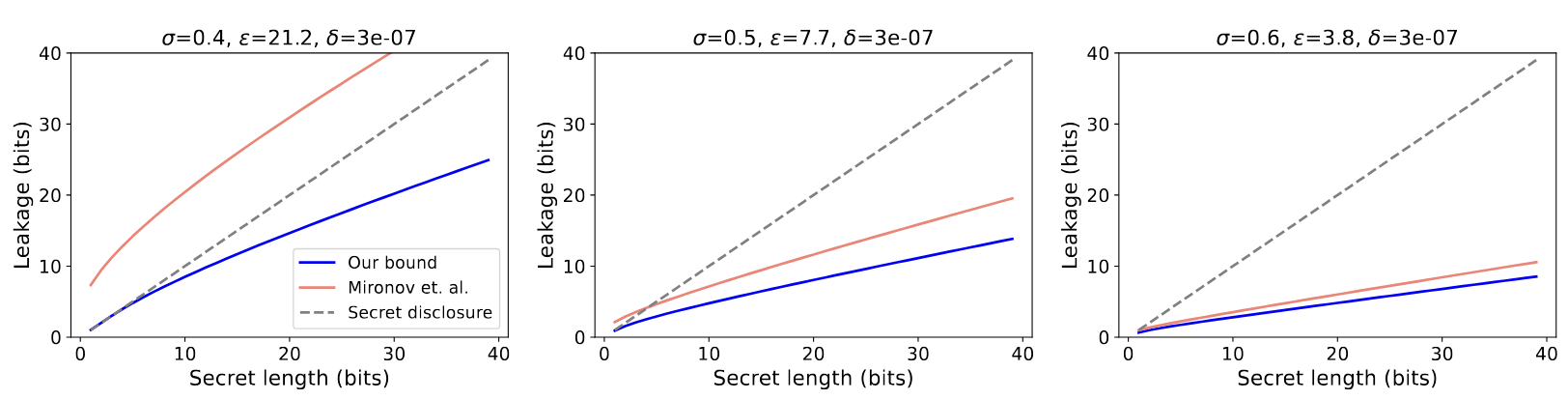 Comparing epsilons under secret extraction, Stock et al (2022)
Comparing epsilons under secret extraction, Stock et al (2022)
The charts above show the authors' results compared with an earlier paper on differentially private deep learning. You can see that for both papers, the epsilon choice, which is a critical part of effectively applying differential privacy, has a direct effect on the ability to extract a secret. You can also see that as epsilon lowers, so does the ability to extract that secret successfully from the model. In case it isn't clear, these results are specific to their implementation and shouldn't be used as evidence that every system will behave the same way.
If you've used differential privacy for training before, you might be worried that it cannot be applied successfully to today's largest models and still achieve accuracy. However, a Google Research group was able to pre-train a BERT model in 2021 achieving 60% accuracy, less than 10% "worse" than the non-DP counterpart. In addition, DeepMind just released their first differentially private Gemma model, which scored quite high on several benchmarks and is available as an open weight model.
Interestingly, differential privacy can be used to successfully protect other parts of the machine learning infrastructure from potential information leakage. In research from Duan et al. (2023), the authors discovered that they could successfully generate privacy-preserving alternative prompts via a differential privacy mechanism when using a blackbox LLM. These differentially private prompts leaked less information when the prompt came from a private prompt source. This can be useful for real-world use cases, such as when you ask a Code Assistant to update confidential code.
Similarly, research around MIAs shows that differential privacy is an effective protection. When investigating "label-only" MIAs, where the model only returns the label (no confidence interval), Choquette-Choo et al. (2021) found that "training with differential privacy or strong l2-regularization are the only current defenses that meaningfully decrease leakage of private information, even for points that are outliers of the training distribution".
Okay, I'm sold! So, how can you actually implement differential privacy in a deep learning system effectively?
How does it work?
Differentially private stochastic gradient descent (DP-SGD) is the traditional and still often used approach to training models with privacy. The definition comes from Abadi et al. in 2016, and I highly recommend watching this video on how it works, especially if you are a visual learner.
Essentially, DP-SGD allows you to use the same deep learning libraries you would normally use (like PyTorch) and apply gradient clipping, averaging and carefully selected noise to protect the individual examples. The process looks like this:
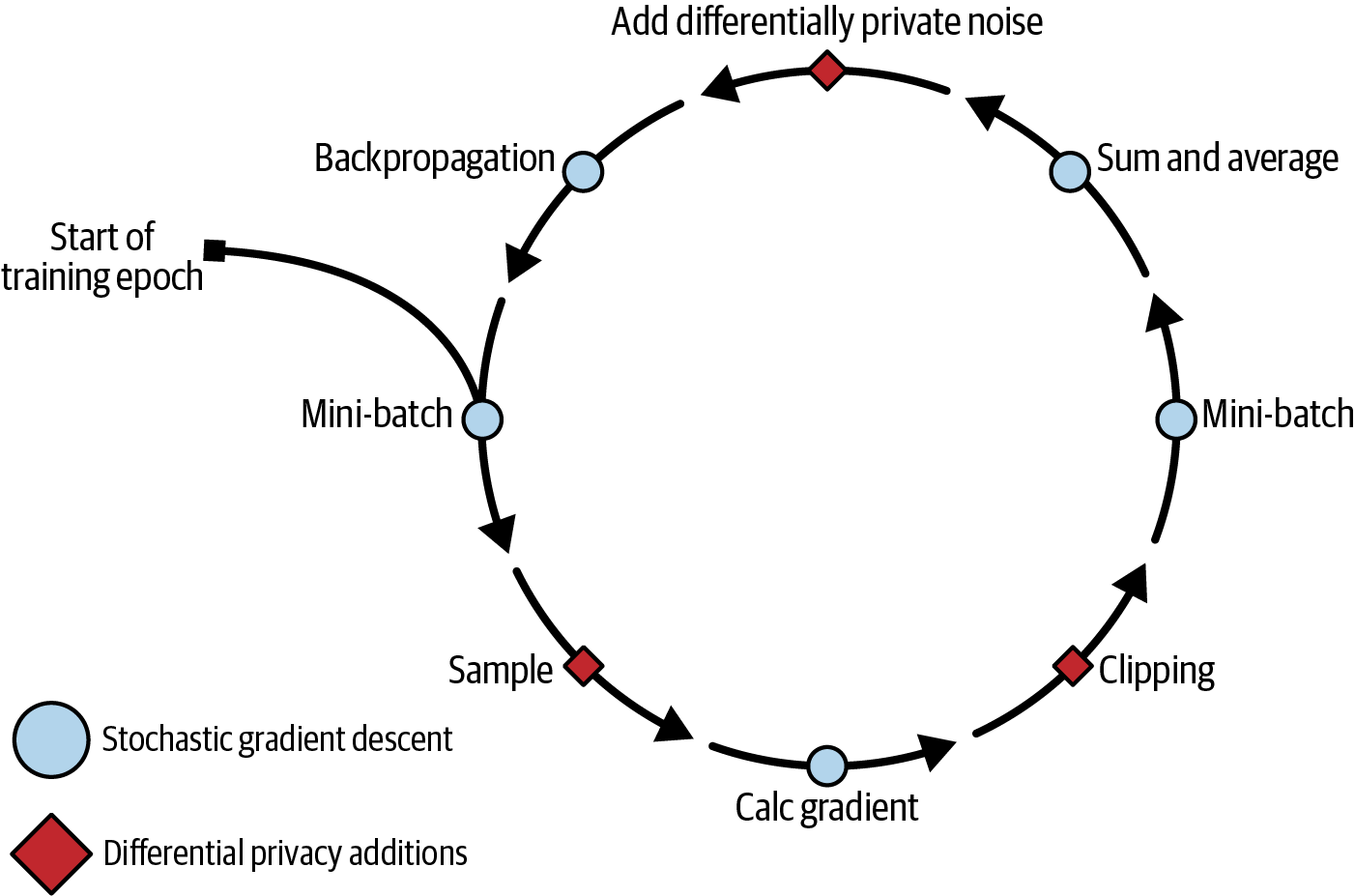
In the graphic above from my book Practical Data Privacy, you see a training epoch that starts with a mini-batch, which is a selected sample of the training data.
This mini-batch is then broken down into a per sample (i.e. assumed per user) size, where the gradient is calculated by taking the derivative of the loss function with respect to the current model weights. Think of this gradient as "how much does this sample change the model".
Then, each gradient is clipped to provide some protection for large changes and aggregated back into the mini-batch (there are several methods to optimize this) with the other gradients: here by a sum and then an average.
The differential privacy noise is then added to the batch, noting that when you group multiple updates together you get additional privacy guarantees. The resulting gradients (now sorted by layer) are used to update model weights and restart the process until training finishes.
Choosing the noise carefully is an interesting avenue of research. Getting this choice right for machine learning systems means still being able to learn effectively, while also providing the same guarantees for individual privacy. As deep learning grew more popular, so did more precise definitions of the noise required in deep learning systems.
The original approach of DP-SGD used particular properties of Gaussian (or normal) distributions to effectively calculate the noise and resulting privacy guarantees. This allowed for the usage of Gaussian noise, which has useful properties in deep learning because many tasks assume Gaussian error or other Gaussian distribution properties.
Building on this approach, a new definition evolved called Rényi differential privacy (RDP).1 RDP provided a new calculation of the bounds provided by the Gaussian distribution that both: (a) simplified the correct choice of parameters for deep learning and (b) allowed for a "tighter composition" so that you can add less noise to get the same guarantees. This didn't change the underlying mechanism in DP-SGD, it just gave a new calculation of the differential privacy parameters (like you read in the definition above) when using DP with a Gaussian distribution noise.2
You might have tried applying DP-SGD or other approaches in the past and it didn't work well; or you heard someone who knows about machine learning say "oh but it doesn't work". Why is this a common experience? It's because there are many ways to tune DP more effectively for your use case and most novice approaches will not work well.
Let's investigate some tips from people who have done DP more than once. :)
Tips from the field
There are several tips when analyzing successful implementations of DP training, especially of large models, like today's deep learning models.
The best advice is:
- Use large batch sizes
- Replace or remove batch normalization/dropout layers
- Set weight decay higher than normal
- If doing input augmentations, include them in the same mini-batch
- Experiment with scaling batch size alongside your learning rate scheduler
- There are usually exploitable ways to modify clipping norm, learning rate, architecture and/or activation choices that are specific to your task, data and sensitivity combinations.
Let's break this down to more intuitively learn from the advice.
Batch Size: When you apply differential privacy, you will be adding noise per batch. This means that the larger the batches the more you can exploit the principles of centralized differential privacy to get more signal versus noise from each round. The research on pre-training BERT used a batch size of around 2M examples. Of course, this can only be done if you have truly internet-scale texts, but it's a useful example nevertheless to think in much larger batches.
Learning from DeepMind's latest experiments, you can calculate the required compute based on your data, batch and privacy parameter choices. This lets you find optimal batch sizes. This finding is probably most relevant if you are training large models, like their differentially private LLM, but the authors think the theory will "scale down" appropriately.
Batch normalization and dropout: Technically, differential privacy is doing this normalization for you, so these layers don't help like they normally would. Research on large-scale image classification says to instead think through ways to replace these layers with something that conveys more signal, like a normal fully connected layer. This also applies to layers like layer-normalization, weight-normalization or any hyperparameters that help with layer smoothing.
Weight Decay: Because noise addition causes more variance than usual during training, it's useful to allow weights to decay more slowly. You might also want to tune this with your batch size and learning rate. Playing with batch scheduling relative to learning rate and the interplay of those two with other hyperparameters is something worth experimenting with for your particular task and architecture. If you don't have the ability to experiment first, it'd be worthwhile investigating the latest research for similar tasks to learn and test new approaches.
Data Augmentations: Because you are calculating clipping and noise addition per batch, it's useful to batch similar data together to get more signal. For this reason, if you are adding example-specific augmentations (as is customary in computer vision) keep the original image and its augmentations in the same mini-batch.
Batch size and learning rate: Because you can expect more variance from DP training and because this will change how your epochs and learning stages work, you'll want to use a learning rate scheduler alongside a batch size scheduler. This can start with large learning rates and then slowly get smaller. Choosing an ideal stopping point will likely also require more attention than normal. Stopping earlier can provide better privacy (i.e. smaller epsilon and avoiding memorization) and ensure you are actually learning from signal and not noise.
Customize for your use case: Much of the research on optimizing DP training exploits particular shifts in activation layers, architecture, clipping norms alongside other hyperparameters. This shows you more than anything that taking some extra time to test a few different approaches will increase in performance. For example, the BERT research found the interplay between the ADAM optimizer and transformer-specific scale invariant layers created challenges, which they solved by changing the weight decay. In 2022 research on large-scale computer vision, authors tuned the clipping norm and learning rate to achieve an optimal performance.
As the field of differential privacy in practical applications grows there will be more learnings, knowledge and practical tips given different datasets, architectures and tasks. It's always worth taking a look at your specific task, data and architecture and debating what could present challenges when using DP training. Doing this while also reviewing the literature, blogs and deep learning library documentation can help solve headaches and more efficiently provide the insight in using differential privacy effectively.
There are also differential privacy modifications for different use cases. For example, there are modifications where only the label needs privacy. This could be the case, for example, where certain features are known by all or most parties but the actual prediction is sensitive (i.e. recommendations, ad conversions or sensitive classification with public features). Ghazi et al. 2021 propose an interesting algorithm that combines Bayesian priors with randomized response for label differential privacy and achieved results that were close to non-private learning. Of course, it could be easily argued that this approach doesn't protect against memorization; so if you use it, it's worth testing using privacy attacks.
Similarly, if your architecture can support a statistical query learning (SQ learning) setup, you can exploit the structure of these queries to implement differential privacy mechanisms at summation points.3
Each win you find for eeking out better performance might come from some tradeoff of memorization or leakage from your training examples. It can be easy to apply differential privacy without paying close attention to the goal you have at hand. Don't forget to actually test your memorization using MIAs and extraction attacks to measure what is "good enough" for your use case.
Framing the problem appropriately
For any implementation of differential privacy (deep learning or otherwise), framing the problem is an essential and complex step. To do so, you need to:
- Choose what you are trying to protect for your data and use case (i.e. privacy unit)
- Understand the data well enough to decide on things like clipping and bounds, or use a library that will help you with this choice
- Evaluate preprocessing steps and determine if they change any of those choices
- Find a reliable and audited DP implementation, like Opacus from PyTorch or tensorflow-privacy, and understand how it works
- Train your DP model and test any approaches to increase performance
- Run privacy testing on resulting models to increase your confidence that you've achieved the utility and privacy you wanted
NOTE
What is a privacy unit? What are bounds?
When using differential privacy, there are a few things that need to be decided to effectively protect individuals. One of the things to define is the privacy unit. What exactly are you protecting? What is that one small change in the data you'd like to avoid revealing to give people plausible deniability and protection? Often the privacy unit is the contributions of one person, but this could also be of one household, or it could be smaller, like you want to protect every contribution individually (i.e. every training example separately, but not, let's say all examples that came from one person's Flickr account).
Once you've defined the unit, you need to figure out what bounds need to be set (or already exist). For example, if you choose a privacy unit of each training example separately, then the bounds for DP-SGD would be how much any one example can change the loss calculation and gradient updates. To do this, you determine a clipping threshold which essentially acts as a maximum value of what any example can contribute to the gradient updates.4
Note that it's generally good practice to clip extremely large gradients during training as outliers or erroneous examples can have an uneven effect on training stability.
I recommend playing around with this interactive visual from Google to get an idea of how clipping and differential privacy affect machine learning models.
Any one of these steps is hard without differential privacy expertise, but essential for the team to learn how to train safer models together. By practicing these skills, you and your team will become both more familiar with how privacy works in real systems, and also able to leverage that knowledge to bring differential privacy into more use cases.
In the next article, you'll explore some cautionary tales of using differential privacy and evaluate open problems in using differential privacy to address deep learning/AI memorization.
Acknowledgements: I would like to thank Damien Desfontaines for his feedback, corrections and thoughts on this article. Any mistakes, typos, inaccuracies or controversial opinions are my own.
-
Rényi DP is similar to concentrated differential privacy, if you are familiar with that approach. If not, check out Desfontaines's great introduction to it! ↩
-
There's a great video from Ilya Mironov, the author of the paper, should you want a deeper and longer introduction to Rényi DP. ↩
-
I recommend reading through Tumult Analytics' documentation on choosing and applying bounds if you are new to this step. ↩