Gaming Evaluation - The evolution of deep learning training and evaluation
Posted on Di 26 November 2024 in ml-memorization
In this article in the series on machine learning memorization, you'll dive deeper into how typical machine learning training and evaluation happens, a crucial step in ensuring the machine learning model actually "learns" something. Let's review the steps that lead up to training a deep learning model.
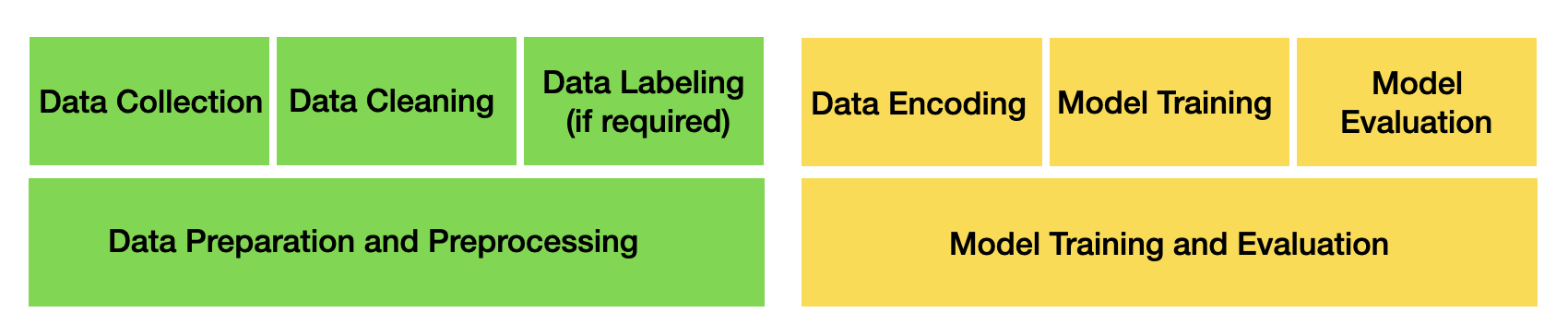 High-level steps to train a deep learning model
High-level steps to train a deep learning model
You've already learned the initial stages that lead up to training a model -- namely, how data is collected and sometimes labeled (depending on the "task" you might need labeled or unlabeled data). After the data is processed, cleaned and saved, it will likely be stored in files, document stores or other distributed data architecture setups for easy access from the data science and/or machine learning team.
Prefer to learn by video? This post is summarized on Probably Private's YouTube.
In a typical machine learning setup, the team uses a dedicated or on-demand GPU cluster or other machines that accelerate and parallelize machine learning training. This special hardware ensures that the massively parallelizable linear algebra computations run as quickly as possible, as you learned when reviewing AlexNet.
At this point, the team will also decide:
- what data and task are relevant
- what model architecture(s) they will train
- an evaluation and validation strategy and dataset to evaluate the models
The simplest and the most common way to answer the data question in a) and c) is to use the data you've already collected and randomly split it into training and testing datasets. This is appealing because it ensures both datasets are similar, making evaluation easier and ensuring all data undergoes standardized preparation and preprocessing. Also it's data you already have, so you don't need to figure out how to collect more data.
Nearly every machine learning algorithm or architecture has hyperparameters, which are variables for the architecture or algorithm. These are usually initialized directly if you have an idea what some of the values should be, or initialized randomly. If you choose to use random initialization, or to search a variety of values for the best initialization, you might perform many parallel training initiations to see which creates a better model.
In conjunction, you can use cross-validation, where multiple models are trained and evaluated on different splits in the dataset and with different initializations of the hyperparameters.
When using cross-validation, your data split might look like this:
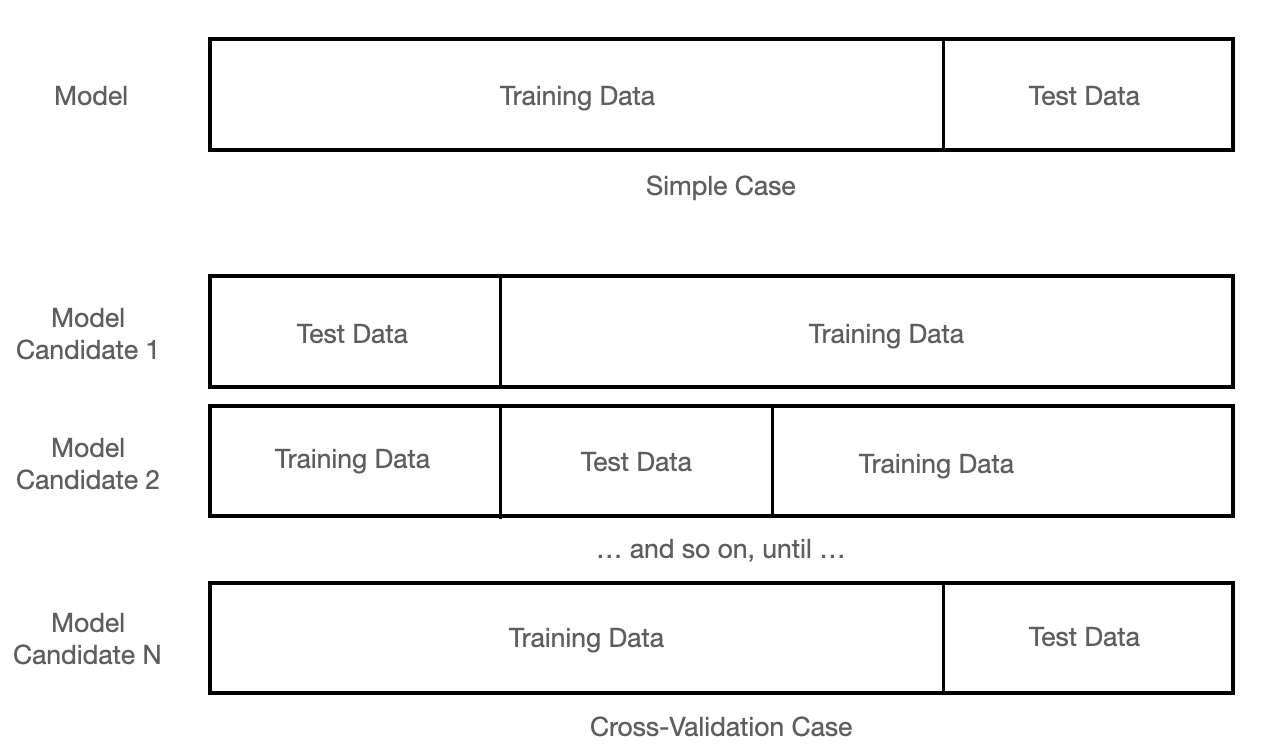 A visual example of training and test splits
A visual example of training and test splits
In a perfect world, this is fine, because the data has been properly cleaned, is attributed correctly and you know that it's high quality data. You presume the data is free and available for use (i.e. data protection compliant and not under special licensing or copyright). You also presume it is representative (i.e. it doesn't have sampling biases) and any labels are correct and appropriately representative. Unfortunately, our world is not perfect.
Instead, as discussed in a previous article, the data often has a significant mass of "typical" examples and then a long tail of more novel examples. Some of those novel examples are likely just errors and mistakes in labeling and collection. Some of the popular examples will repeat themselves either pixel-for-pixel and word-for-word or in chunks with close approximation, like beginning a business letter with "To Whom it May Concern".
This brings several problems, some which contribute significantly to the memorization problem. Let's evaluate them alongside the typical training process.
Data Quality, Duplication and Preprocessing / Cleaning
Internet-scraped data has many quality issues, but so does data specifically collected for a task, due to many of the societal, measurement and population biases described in the data collection article. If your goal is to create an accurate and representative view of something like everything you can see outside, or even a smaller task, like recognizing every voice speaking English for speech to text, you will certainly miss some representations and you'll likely also run into training data quality issues.
Data quality is a hotly debated topic within machine learning and data science. Some machine learning scientists presume that if the errors only represent a small portion of the data, they will essentially be regularized out of the model. This presumes two things: (1) the errors represent a small portion of the overall data collected and (2) the model will not memorize erroneous data.
If a data scientist presumes that there are significant quality issues with the current dataset, there should be a plan to deal with the problems. An example plan could look something like the following:
- Test for duplication and remove duplicates using near-match or perfect match search strategy. Remember that near-match is a hard problem and can require human intervention and labeling.
- Test for realistic bounds or patterns and regularize or remove data outside of those bounds. For example, find and remove overexposed photos.
- Apply domain-specific criteria to detect problems and either correct or remove those issues. For example, remove poor quality boilerplate or spam text.
- Determine other preprocessing to ensure all data is similarly standardized and irregularities have hopefully been removed. This can require things like removing outliers, normalizing data and filling in missing values.
This is a difficult task due to the input data complexity, especially when you are using non-tabular datasets (i.e. not data in rows and columns). Is a cropped photo of a larger photo a duplicate? What about text that varies by one paragraph? What are "realistic bounds" for outliers when it comes to PDF documents? Many of these are open research problems that require significant domain experience to address properly - which most data scientists don't have by default.
Due to this skill mismatch and lack of resources, usually only the most rudimentary quality checks and preprocessing happens. This data is then considered "clean" for the following training and evaluation steps.
Sampling Bias
Sampling bias is data bias or error that comes from the way the data is collected and used.
In deep learning, there are two forms of sampling bias. The first occurs during data collection, which you learned about in the last article. This bias is seen in the skewed representations and societal biases, but also in other features, like the represented language style and context. If you are using Wikipedia, the writing has a certain style, versus if you use arXiv (another popular source) or Reddit (a very different style of language, even though it will also be mainly in English). These choices greatly impact how a language can learn and reproduce linguistic style and writing.
The second type of bias is the actual sampling method used to perform the training split and validation in the dataset. In an ideal scenario, you'd study the underlying data populations and make specific decisions on how you'd like to split the training and evaluation/testing data so that each sample has an adequate representation of the population information you are trying to learn.
In a perfect scenario you might even use a separate test and evaluation set that you specifically collected and labeled to ensure you know the data quality and provenance -- even if it slightly deviates from the original training data. For example, if you really wanted to evaluate a system with unseen data, you could collect the test and/or evaluation data via a separate process. Let's say you are testing a chatbot for customer search and knowledge base surfacing. You could collect the test and evaluation set by leveraging your customer service department -- who could create an entirely separate evaluation set based on their knowledge and experience. You could expand this dataset by sampling real customer queries of the system when it launches or in a beta setting and having the customer service team appropriately validate, label and annotate or enhance the dataset.
In reality, a data scientist likely uses a built-in preprocessing train-test split that takes the entire data and runs a random sampler across it. Again, this probably wouldn't be a problem if the data always had a normal distribution and was high quality, but this is not usual with the large scale scraped or publicly available datasets. This means that random sampling is not actually representative of what you are trying to learn, and certainly not always a quality you want to reproduce. It also means the chance of sampling near-matches, extremely similar data to your training data, and one-off outliers or errors is high (because of the long tail and prevalent collection methods).
This sampling bias impacts both the performance of the model on the data, but also the progression of model training, which brings us to our next problem.
Training batches and rounds
In deep learning setups, data science and machine learning teams use multiple training rounds to ensure the model "learns".
Usually, training is broken down into iterations called epochs and then a smaller iteration called steps. This is then repeated as long as needed until the model scores high enough or the team decides it isn't working. When reviewing the following process, I want you to imagine this process happening thousands, if not hundreds of thousands of times, meaning the model processes the same data many thousands of times, each time trying to better "learn" from that data.
Let's investigate a typical training epoch:
- Before a training epoch can start a data batch size needs to be defined. Usually batch sizing is correlated to the dataset and hardware at hand. For large models and accompanying datasets, usual batch sizes start at 128 data examples.
-
At the beginning of a training epoch, a sampler is used to select the batch from the training dataset. The default sampler is "random" and breaks up the full training dataset into a particular number of batches. Note that the randomness is dependent on what hardware is being used, and therefore in many cases not truly random.
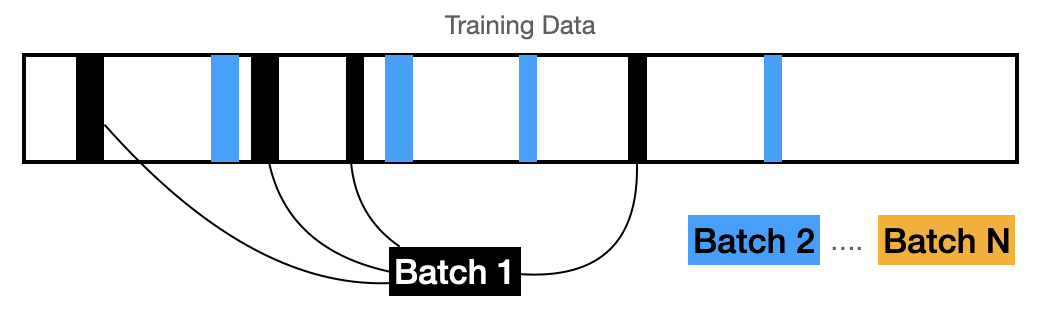 Visual example for batch selection
Visual example for batch selection -
The examples in the first batch will be processed through the model to create a prediction or output (similar to how it works when a model is used normally to predict a label or the next token). This processing activates nodes and layers across the model's network based on the model's weights and biases.
-
The final layer of the model will predict a class or make another prediction, such as a token or other generative output. This response will be compared to the training data itself, such as the label or the next series of words in the training example.
Visual example of a loss calculation. During training, you continuously predict and measure loss to sequentially improve the model response.
-
Depending on how correct or likely that answer is, there will be an error calculation (often called a loss function). You can choose different error calculations, but many are based on the concept of cross entropy, which roughly tries to say how likely the model response and the training data come from the same population (i.e. how predictable or "normal" is this response?). The error is used to derive the updates for all of the weights in the network to attempt to correct future responses. If the loss is large, this will highly impact the weights for those examples. This means outliers and potential erroneous inputs can have an outsized impact on the model training.
-
Once the parameter (weight and bias) changes for each layer are calculated, backpropagation begins. The process updates each layer with the new weights and the training step is complete. These updates usually happen at the end of the full batch.
 Visual example of corrections to particular weights based on error. The stronger the red border representing error, the larger the shift in the weights and biases related to that particular node.
Visual example of corrections to particular weights based on error. The stronger the red border representing error, the larger the shift in the weights and biases related to that particular node. -
Then, the next batch is selected and the training step begins again. This is repeated until the epoch is complete, so the model has seen all possible training data once.
- At the end of an epoch a subset of the test data is selected to evaluate the model performance. The performance of the model on that data is usually shown via a dashboard, so that the machine learning scientist, data scientist or engineer can determine if the training is going well or if it should be stopped because the model either isn't performing and something catastrophic has happened. Sometimes, the team will also stop training in what is called early stopping because the model has reached a good or optimal performance, where they assess that further learning might result in overfitting or won't provide much additional gains.
It's common to train for multiple epochs, meaning the entirety of the training dataset is used multiple times. For overparameterized networks, which you'll learn about more in a later article, this repetition is significant as the models require hundreds of thousands of "full passes" (i.e. one training epoch on all data) to reach peak performance ([see: early work on scaling Generative models and NVIDIA's scaling language model training to 1T parameters).
To dive deeper into the workings of these steps, take a look at the Neural Blog's Forward Pass and Backpropagation example.
By reviewing this process, you can infer that uncommon examples have a more significant impact on network weights compared to more common examples. Because there are also fewer of them, the model weights must account very specifically for those examples in order to achieve optimal performance. You will come back to this insight later in this series, but let's first evaluate the evaluation process.
The Myth of "Unseen" Datasets
The training steps of a deep learning model require that the data is seen in its entirety usually multiple times. If the test data is sampled from the same dataset, how "unseen" is the test data?
The split between test and training is often random, and yet the datasets are often collected from similar samples. Let's take a look at an artifact from some research around memorization to see how this plays out.
 Example training sample and test sample from ImageNet
Example training sample and test sample from ImageNet
On the left is a test data sample, with the accuracy of the model's prediction written underneath it (75%). But on the right is an example from the training data which most influenced the weights to guess "correctly" on the test data. The photos are clearly from the same photographer, on the same day, of the same thing. And yet, this is called "unseen" data?
Presumably, you want the test data to be completely unseen so you can tell how well your model is actually generalizing. Generalization is used to describe a quality that the model has learned how to generalize on patterns, rather than to overfit the training data and perform less well on unseen or real-world data.
Since you learned about the long-tail distribution of the scraped "real world" data, the chance that the test example is truly unseen is unlikely when sampling from the same collected dataset. If you sample from the peak of the distribution, that data is massively duplicated, so this is certainly not unseen data. If you sample from the tail, you do have a much higher chance of "unseen" examples, but ideally you also want to learn most of the tail in order to generalize, which means you need significant data points from the tail in your training dataset.
In fact, some of the best research on the problems of imbalanced classes, which is an effect of the "real world" distributions, guide practitioners to oversample the tail as training examples, leading to more "balance" between the peak and the tail. If you oversample the long tail for training, then this also means there is less of the tail for testing, and you again get in the cycle of testing mainly with common examples, which the model should certainly learn.
Why is this happening? This isn't representative of actual learning, and it certainly won't work well in the real world if this is the performance. Let's investigate one potential factor in how this occurs.
The pressure to publish and "Benchmarks"
In academia, there is more pressure to publish than ever before. Especially in fast-moving fields like machine learning or AI, researchers and students must attempt to create novel, breakthrough work at record speed. But usually novel work takes time, it takes inspiration, it takes many trials and errors and blockers until you have a really interesting idea and approach.
So, how do you keep publishing at a high speed if you don't have the time to actually explore ideas fully? You aim for benchmarks!
Benchmarks and their accompanying leaderboards have become a gamification of machine learning research.1 A benchmark dataset is often introduced as a paper itself (bonus: you get a paper published by creating a new benchmark) and usually introduces a particular task and dataset -- such as a generative AI model passing the bar exam. After publication, someone will beat the initial model who wins the benchmark (another novel paper!). Then, someone else will beat that model (yet again a novel paper!).
But is the data representative of real-world problems? Is the data diverse and representative? Is the testing data "unseen"? Is the benchmark useful for the use cases that people need solved?
Kaggle Culture and the origin of Leaderboards
Kaggle is an online machine learning community that started in 2010 (and has since largely been replaced by HuggingFace).
Kaggle hosted many popular datasets and competitions in the early-to-mid 2010s. The goal was to share models that beat other models at particular machine learning competitions or tasks. This usually involved overengineering models with no attention to generalization, making them bigger than ever, using every possible feature you could think of, using (now dated but then trendy) techniques like AutoML, where feature extraction is automated and becomes opaque. You could often win money, internships or even get hired based on your Kaggle status.
There are several known examples of teams or participants figuring out how to train on the test dataset, or directly encode the not very well hidden test dataset.
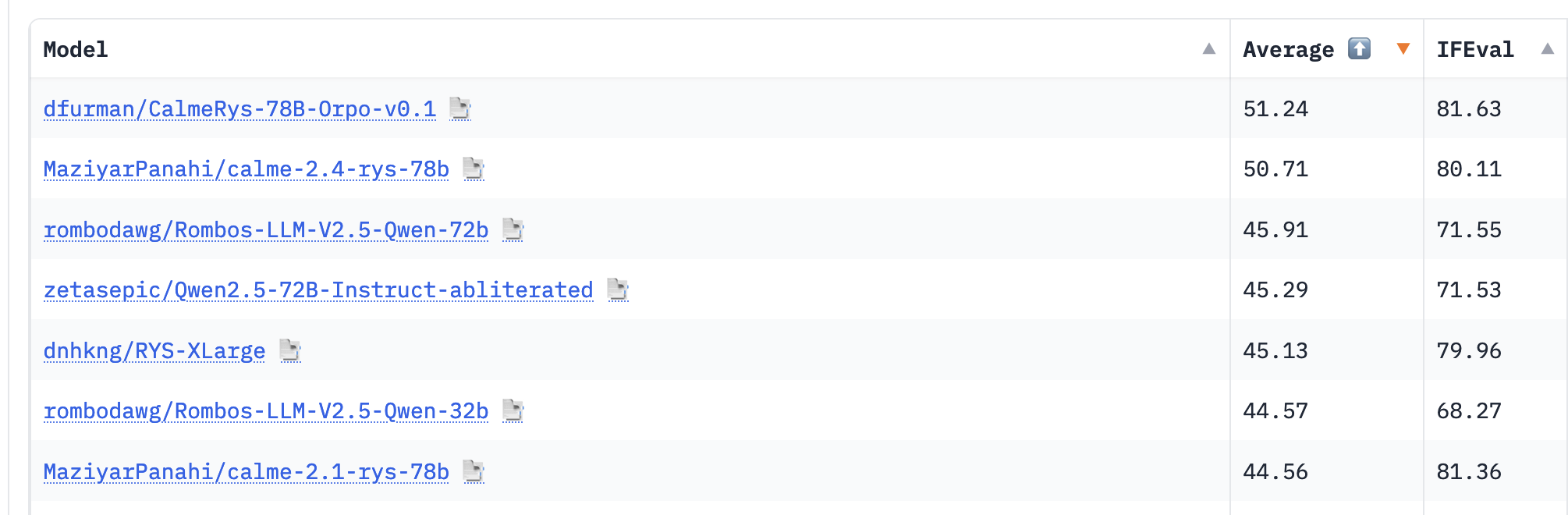 An HuggingFace LLM leaderboard, where all models are fine-tuned by individuals and "outperform" the base model trained by large expert teams. Can you guess what the fine-tuning data is?
An HuggingFace LLM leaderboard, where all models are fine-tuned by individuals and "outperform" the base model trained by large expert teams. Can you guess what the fine-tuning data is?
The entire cultural goal was being the #1 machine learning model, and for that, you would do anything to squeeze out extreme accuracy, even if it wasn't really a very good machine learning model afterwards. This "winner takes all" leaderboard mentality still exists in today's machine learning community, now as Hugging Face leaderboards.
The problems outlined in this article contribute significantly to common problems in real-use applications, like models never launching into production.2 These realities also contribute to "model drift" or "data drift", where model performance shifts when launched into real-world use cases in production settings. But where did the data drift to? Simply outside of the carefully collected training dataset representation.
A question to others in the machine learning community: How sure are we that we are getting the population right? Are we using basic statistical thinking to model our data collection approach? Can we learn from social sciences on population representation? Are we focused on creating the best models for real-world impact? Are we challenging current data collection methods for bias, misrepresentation and (in many ways) lack of real world applicability? Can we foster better understanding of what AI models humans want and start our evaluation sets there?
In the next article, you'll use what you learned to review how massively repeated examples are memorized. We're diving into the "heady" part first. ;)
I'm very open to feedback (positive, neutral or critical), questions (there are no stupid questions!) and creative re-use of this content. If you have any of those, please share it with me! This helps keep me inspired and writing. :)
Acknowledgements: I would like to thank Vicki Boykis, Damien Desfontaines and Yann Dupis for their feedback, corrections and thoughts on this series. Their input greatly contributed to improvements in my thinking and writing. Any mistakes, typos, inaccuracies or controversial opinions are my own.
-
This obviously wasn't the initial intention of benchmarks, which was more about finding useful metrics that were (hopefully) not directly in the training datasets. I don't think the mentality I describe applies to all researchers or practitioners; however, it's still become a serious cultural and strategic problem in achieving useful model metrics and it's deeply affected model development. On the day I published this article, there was a really nice MIT Technology Article on the problems of benchmarks. ↩
-
There are online methods for evaluating models in real-time, like measuring performance metrics directly in the application using the model. Companies can and do develop these near real-time, online evaluations and sometimes even directly learn from production environments or deploy new models automatically when they perform better than the current ones. I would caution, however, that this lack of human oversight of the incoming "test" dataset can reproduce the same problems as biases in the collected data -- probably even more so if your application isn't used by billions of people (and even then, who and who not?). ↩