Machine Unlearning: How today's Unlearning is done
Posted on Fr 19 September 2025 in ml-memorization
Building on our understanding of machine unlearning and its varied definitions, in this article you'll learn common approaches to implementing unlearning. To effectively use these approaches, you'll first want to define what unlearning definition and measurement fits your needs.
In current unlearning research, there are three main categories of unlearning implementations:
- early approaches that require specialized feature and model setups
- today's fine-tuning and training approaches for large deep learning/AI models
- a sampling of novel and interesting approaches
Are you a visual learner? There's a YouTube video on this article (unlearning methods) on the Probably Private channel.
This is all part of a series on AI and machine learning memorization.
Early Approaches
Unlearning has been a topic of study for 10 years. Early approaches didn't target deep learning exclusively, and therefore there are some interesting and effective ways to manage the problem in other types of machine learning.
One of the first papers on Machine Unlearning was Cao et al (2015). The research focused on a variety of unlearning use cases like privacy concerns or removing erroneous or outdated data from the model.
Their approach combined data subsets to generate aggregated machine learning features, which you can think of as input variables. Then those variables were used in combination with algorithms to predict outputs. Because of this structure, you can remove a single contribution to a feature or several summed contributions without needing to retrain the model. This approach works for statistical query learning algorithms, which allow you to perform queries of the underlying data and use those as direct algorithm inputs.
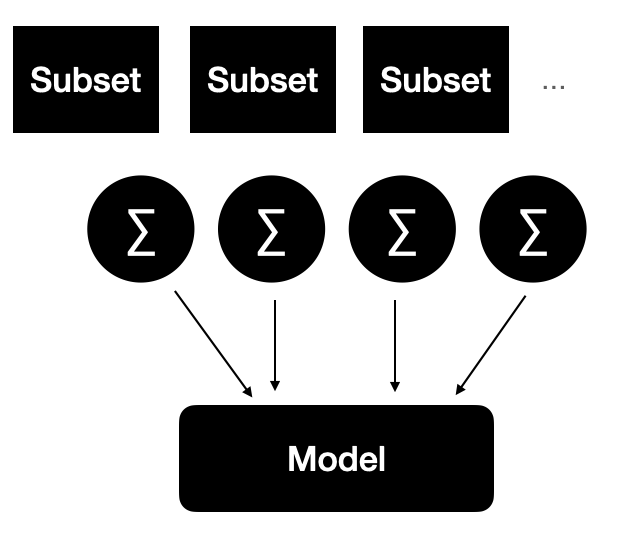
You can adapt this approach for deep learning by training separate models which act as an ensemble. Bourtoule et al. (2020) developed an approach called Sharded, Isolated, Sliced, and Aggregated or SISA learning. As the name suggests, this shards the data and trains a model from each shard. Those models form an ensemble that predicts the outputs as a committee.
You can then remove or retrain just one model rather than the entire learning system. The authors also used checkpoints so you could potentially "roll back" one of the models to an earlier checkpoint before that exact data point was seen. So if you want to unlearn or forget a particular data subset or even one data point, you can amputate that shard from the model and retrain just the smaller model starting at the previous checkpoint.
This inspired another approach called adaptive machine unlearning (Gupta et al., 2021). The authors were working on adaptive deletion requests (i.e. requests that might target several data examples and resulting model behaviors that are not independent). They wanted to retain essential information in the model but still allow for user-driven deletion requests. To do so, they use an approach inspired by differential privacy and information theory, which inserts randomness into the learning and unlearning process to better guarantee that the data points do not leak as much information.
However, these approaches don't map to today's large deep learning architectures, where data is first transformed directly into embeddings instead of features, and those embeddings are usually also sequence-related (like words in order, or pixels in order). These approaches are useful for a subset of machine learning and deep learning, but not all of what falls under today's "AI".1
Luckily there is a series of approaches focused specifically on deep unlearning for these large embedding-based models.
Deep Unlearning
For deep unlearning, most approaches exploit the same learning methods to instead unlearn. Recall that training calculates values across different nodes and layers in the deep learning network and calculates the error (i.e. how much the model was "off target"). This error, represented in gradients, is then used to update the model parameters.
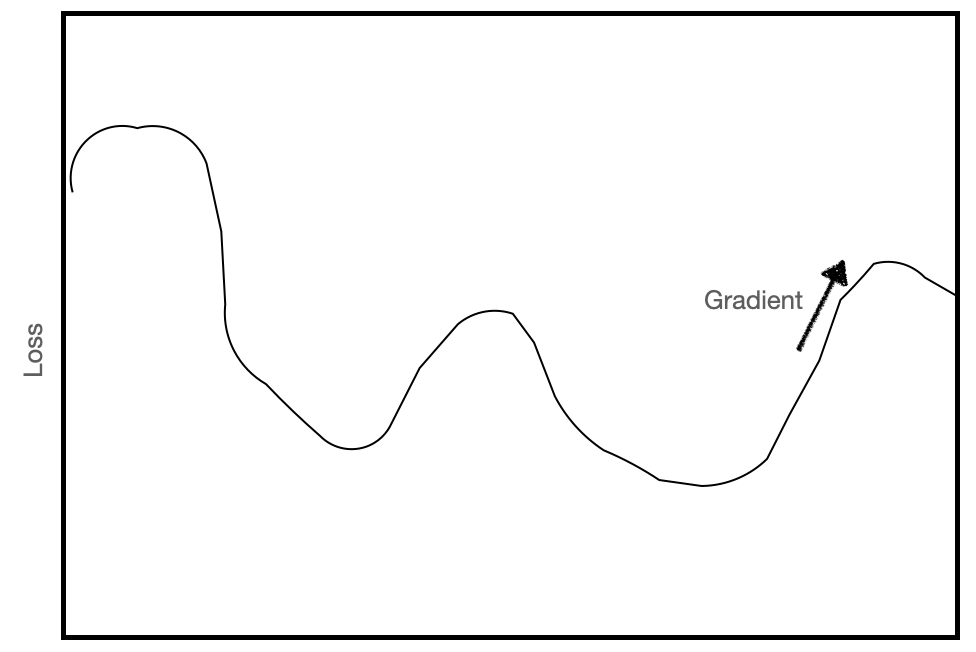
What is a gradient? You've probably calculated the slope of a line which connects two dots. This helps you measure the change from one dot to the other. Imagine that if those dots are moving, you can calculate both the change between them and the rate of change.
A deep learning model operates as many functions. To adjust those functions to be more accurate, you compare the data to the current model functions and see how "wrong" the functions are. Doing this by looking at the size and rate of the error produces gradients. These gradients represent the loss function of the current model functions compared with the training data in that batch.
A gradient always maximizes the function, which here would maximize the loss function (error). This is why in machine learning, you descend the gradient (gradient descent) to minimize error. Because the math is too computation-intensive to calculate the gradient for every example and every parameter, this calculation is approximated or averaged/batched.2
For each training batch, the error rate is calculated across the batch and the average change is used to send approximate updates to the model parameters. The parameter updates happen via a process called backpropagation.
Gradient descent via backpropagation first happens in big jumps, where gradients are large, and then updates slow down as the network gets closer to the approximate representation of the task. Since you usually start from a "random guess", early training rounds happen in large steps. The middle training rounds usually convey improvements for majority classes and as you move to later training rounds, the nuances of the outliers, the less frequent classes or smaller representations will change. Sometimes this can result in over-optimization/overfitting on the training set, but that's usually for smaller networks than today's largest AI models.
Unlearning different parts of these weights, especially calculating how to unlearn specific examples, is difficult to disentangle from the other learned representations. Because network layers and their weights and biases are not easy to inspect or understand, it also makes the unlearning task intransparent.
Many of the deep unlearning methods essentially reverse this process, by:
- ascending the gradient for a particular example or set of examples
- maximizing loss on an example while minimizing loss for several other examples you don't want to forget
- maximizing the forget examples to point toward an alternative label/output (i.e. calculate loss and move parameters towards a new generic answer/label)
- some mixture of the above combined with classic deep learning methods (like more fine-tuning, freezing weights, bounding loss contributions, etc.)
Looking at the Google/NeurIPS Unlearning Challenge, more than half of the top 10 models did some combination of these approaches, which I will call sophisticated fine-tuning for unlearning.
There's another batch of deep learning methods which compare the fully retrained model with the unlearned model. This can use methods like divergence or distance measurements between the networks or mix those measurements alongside fine-tuning methods.
But since networks can exist in divergent states and have similar outputs, this can be prone to error if done without attention to the actual output impact. In successful approaches, this comparison can take the form of a student/teacher setup, where the student is told to "stay near the teacher" but unlearn a particular set of examples.3
In general, these approaches work well with some unlearning definitions. The model ends up scoring lower on the examples they are unlearning and sometimes can no longer be attacked to reveal what they know about those examples.
Unfortunately, these methods are prone to other problems:
- memorization/overfitting on other classes and their examples, especially if the population is small
- forgetting important task information, sometimes called knowledge entanglement
- performing worse across other metrics and classes (i.e. loss in model utility)
- unstable and unpredictable unlearning4
- scaling issues (i.e. trying to unlearn 1% of the training data is much easier than unlearning 10%)
You'll come back to several of these issues in the next article, where you'll learn about attacks on deep unlearning.
Because there aren't standardized metrics to compare these approaches, and since forgetting is heavily linked to data and task properties, it's difficult to determine the most relevant approaches for your particular combination of data, task, model architecture and unlearning result. If you're a researcher working in the space, focusing on practical comparisons would be a useful contribution -- particularly across large parameter models and complex tasks (i.e. information-intensive learning).
In reading more than 50 academic unlearning papers, I came across several novel ideas and approaches. I'll summarize a few exceptional ones in the final section. My goal isn't to instruct you to use these approaches, but I'm hoping to inspire creative interpretation and thinking when viewing the unlearning task.
Novel approaches to unlearning
One interesting approach is to first figure out how easy or hard it would be to unlearn a point and still generalize well. Think of it as a litmus test for the ability to unlearn a particular example or subset.
In "Remember What You Want to Forget: Algorithms for Machine Unlearning" the authors define machine unlearning by borrowing concepts from differential privacy. In their definition, an attacker who can actively choose the forget set should not be able to tell the difference between querying the unlearned model and a model that has never seen the forget set. They found lower bounds on unlearning, where a model cannot unlearn anymore without removing most of the utility on the retain dataset.
Their unlearning method continuously calculates model updates to balance between the forget data points and relevant retain data points. They use sampled noise to provide stronger guarantees so the attacker might not be able to tell the difference between the models. This is inspired by differential privacy.
A different approach from Golatkar et al. (2020) looks at the problem via information theory. The authors calculate what information exists in the forget sample while holding the information in the retain sample high. Since computing the Fisher information matrix is too difficult within a neural network, they approximate the matrix's diagonal as part of their scrubbing procedure.
Others have investigated building unlearning directly into deep learning architectures. Chen et al. (2023) imagine an architecture where unlearning layers are trained as deletion requests come in and combined into model architectures. These layers borrow from the teacher-student ideas in Kurmanji et al.'s work.2
One final interesting approach looks at unlearning an entire class or group by investigating the mathematics of the learned model. Chen et al. (2024) find the subspace of each class at each layer, identifying the kernel and null spaces. They then remove the subspaces for the forget class and merge the other subspaces back together. This mimics some of the interesting approaches in LORA fine tuning. After the subspaces are merged, the forget examples are fine-tuned with pseudo labeling (i.e. generic labels).
Many of these approaches came from research and not industry. Will these work in a production-level setup? Are they scalable and efficient in large-scale contexts (i.e. with billion or trillion-parameter models)? Remember: the unlearning promise is that these methods will be cheaper and easier than retraining the models regularly.
Scaling of Deletion and Removal Requests
Most of this research approaches unlearning a small portion, sometimes a randomly chosen small subset of previously learned training data. Is this the problem definition at hand?
Looking at reported industry statistics on California (CCPA) deletion requests, there is a heavy skew of where consumers want their data removed. This could change over time, but presumably the unlearning scale should match the deletion request scale. If a company receives 10 deletion requests a week or less compared with thousands, this changes the available solutions. The same applies to data expiration and retention periods.
Since large tech companies who release large models often release new models every 6 months, this is another relevant aspect to consider. If retraining a new model is already happening, why not retrain without the forget data? How many models are you supporting and serving at once, and under what privacy and consent conditions?
Given the solutions proposed in this article by the leading unlearning research, it makes sense to use unlearning if you:
- have a small amount of deletion requests or expiring data
- have a deep learning model that you trained or fine-tuned in-house on personal data
- don't plan on retraining that model in the next 3-6 months
- have a team that can take research papers and implement them in a fine-tuning pipeline
- can implement and test the unlearning approach achieves whatever metric you define as "good enough"
Since this applies to a very small group of companies, what is a reasonable approach for everyone else?
In general, it would be useful for machine learning companies to focus on:
a) truly public data (i.e. open access and not under copyright) b) enthusiastic consent and opt-in
Enthusiastic consent can lead to fewer deletion requests and create more collaborative and cooperative models, which would build trust in these systems. In addition, it could increase competition and people's ability to choose which organizations they would like to support with their data.
Collaborative data creates a more diverse and participatory set of models, which also provides better understanding of what users and humans actually want from AI systems.
In the next article, you'll look at whether today's unlearning approaches meet the definitions and tests laid out in the initial attacks article, as well as if they open up any new attack methods. In subsequent articles, you'll look at other approaches to solving the memorization problem, like using differential privacy during training.
As always, I'm very open to feedback (positive, neutral or critical), questions (there are no stupid questions!) and creative re-use of this content. If you have any of those, please share it with me! This helps keep me inspired and writing. :)
Acknowledgements: I would like to thank Damien Desfontaines for his feedback, corrections and thoughts on this article. Any mistakes, typos, inaccuracies or controversial opinions are my own.
-
Although there are probably creative ways to think through how some of these could be applied to noise or sharding with a mixture of experts model. ↩
-
For a useful short video, I recommend watching this one from Visually Explained on YouTube. ↩↩
-
Kurmanji et al. (2023) created several student models that are initialized with the original model weights and then diverge from this "teacher" model. The training procedure encourages the students to "stay close" to the teacher and retain data subsets while also "moving away" from the teacher on the forget data subsets. ↩
-
Unlearning in anomaly detection work found that unlearning creates unbounded and exponential loss. This happens because the prediction is already close to correct, then maximizing loss creates very large gradients which erase information in the network. Ideally you want to keep that information by appropriately bounding large losses. ↩