Using Synthetic Data for Privacy in AI/ML Systems
Posted on Mi 13 Mai 2026 in practical-ai-privacy
If you've read Practical Data Privacy, you'll know I'm not a huge fan of synthetic data. As a data scientist and machine learning person, usually I want to use high quality data and only introduce slight deviations by using protections for privacy (like differential privacy).
In my book, I clarify that the small error that differential privacy introduces is trivial compared to the noise of synthetic data. If it's business critical and internal use only, usually you are using real data and you clarify data processing at a policy level (i.e. by stating clearly and transparently communicating how you collect and use data due to its business critical nature).
Note: This article is specifically about when synthetic data is being used for "privacy purposes". There are several other uses of synthetic data, such as dataset augmentation, testing, or transformations for better model performance, which I will not address.
However, it's clear to me now (4 years later), that there are new use cases where synthetic data can help promote privacy in today's AI workflows. For this reason, let's discuss how certain workflows can benefit from synthetic data.
When to use synthetic data for privacy
There are many instances of using data in today's AI settings where additional privacy can be offered by using synthetic data. The use cases that were not as common when I wrote the book is sending large amounts of data to third-party AI vendors.
This can look like the following:
- You are vibe coding and you need data to send to a third-party AI system as part of the engineering workflow
- You are working on AI-supported data visualizations, and want to test out a few vendors before signing an agreement
- You are testing several data extraction pipelines to compare and determine where to build your tool
- You are using a third-party vendor you don't necessarily trust with your real data
These are all cases where having semi-realistic synthetic data can help. But wait! Not all methods are 100% private, which is why I said in the book to be careful...
Thinking of using a vendor for your synthetic data? Stop everything you're doing right now and watch Damien Desfontaines' USENIX talk! Then you can come back to reading when you decide to build your own. ;)
Let's break down a few choices so you can decide the level of privacy and safety you need based on your use case.
How to use synthetic data for privacy
I'll outline three major options I see:
- Fully private dummy data
- Probably Private Tabular (or similar) data
- Probably Private Deep Learning Generated data
Then, I'll share some cool ideas that aren't yet available in production-ready code, but I hope will inspire better thinking around how to build new and interesting ways for thinking through privacy in synthetic data generation.
Let's walk through your primary options first, starting with fully private and also fully synthetic data.
Fully private, "dummy" data
If you just need to ensure that things are properly working or want to build out initial workflows for your AI product, I would recommend using so-called "dummy data". This is essentially fully synthetic data that has whatever properties and attributes you need without actually involving any real privacy risk.
The library I most commonly recommend for this is Faker. It has both Python and a few other language translations and also several command-line tools for easy use.
Faker works by setting up a factory, which you can also use with internationalization. These factories can then produce fake data, like names, addresses, emails, IP addresses, etc.
 An example of Faker Factories
An example of Faker Factories
To use Faker, it works best with fully structured data, like if you are mocking a database or well-structured JSON. If using less well-structured (semi-structured) data, you'll need a strong idea of which parts of that data are important to preserve.
If you have business logic inputs, you could pull parts of your real non-person-related and non-confidential data and mix them with Faker data to get a workable full table.
There are even ways to generate fake documents, which can help if you are testing out new types of RAG based workflows.
If you want to use Faker to create fully synthetic initial data, you can also leverage libraries like numpy and scipy to develop more realistic data factories.
You might start simple, using constraints around things like column or value max/min/mean/median to build a small function. You can leverage these libraries to sample from a Gaussian distribution informed by those properties from your real data. Or to decide what types of other samplers or distributions you might use, such as selecting from a random uniform for categorical columns (if that fits your expectation).
Once that's working you can use more dynamic approaches, like learning a distribution via a scikit-learn Clustering or a pymc3 Bayesian model based on your data. Then you can "sample" from an artificially created representative distribution using what you learned.
I explored some simple ideas in my datafuzz repo in case you want a few small snippets to get your ideas flowing.
If that's too much time investment to craft your own, or there are intricate correlations that you're not sure about and would like preserved, you can move onto other methods for synthetic data generation, like libraries that can help you find these relationships and leverage them to create semi-realistic data.
Note that the further in this article you read, the less privacy guarantees you can offer....
Probably Private Tabular Data
In 2018, NIST held a synthetic data challenge and the winning contribution was a clever way to produce similar enough data while having provable privacy guarantees. The team who won used 3-way marginals with differential privacy to create a synthetic data generation graph.
How does this work?
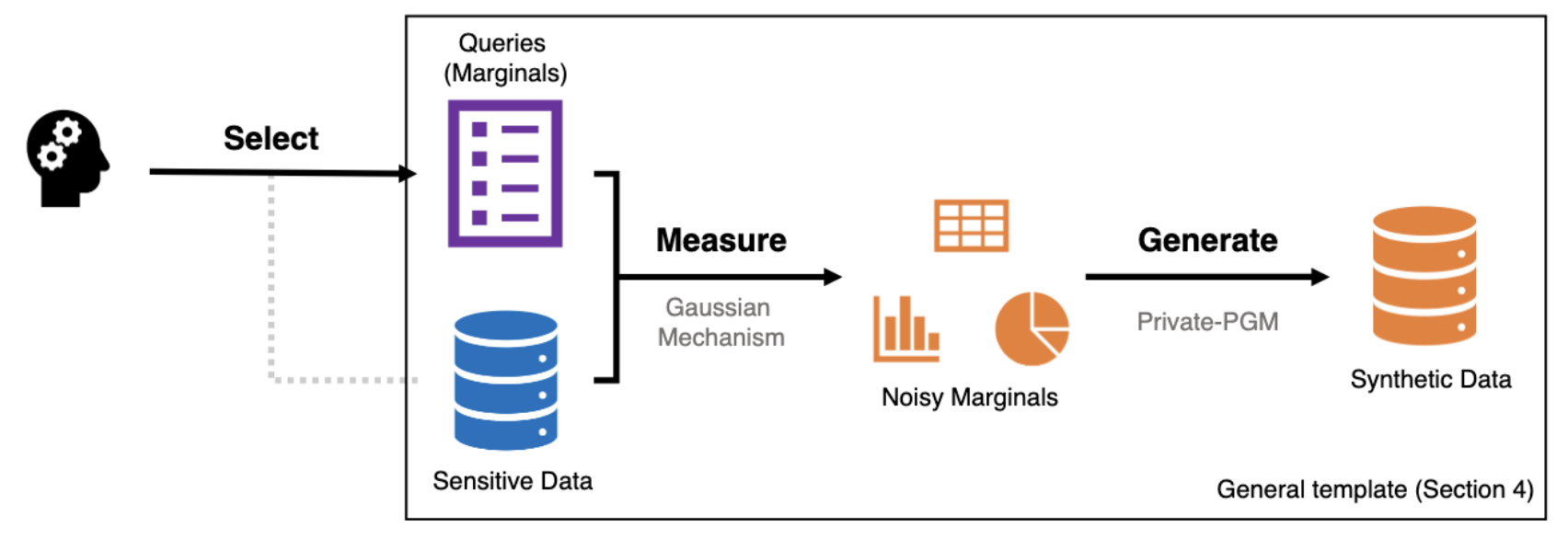
Let's walk through each step:
-
A set of queries that are to be answered come in via a user (or in this case the NIST testing that was run as part of the competition).
-
Those queries are run on sensitive data into marginal groupings. This means you group the query responses with a variety of attributes, let's say location, gender and income group, since they were using US Census data.
-
From those real marginals, you pull differentially private marginals. This basically means you now have noisy histograms based on the real data, but with some error to preserve privacy.
-
Then you use a graph optimizer (more here) to find a response based on the noisy marginals to "solve" the original query. This is then the actual query response which is both informed by the real data, but with significant privacy protections.
Compared with deep learning-based approaches that were submitted to the contest, this approach is simpler and cleaner and has provable guarantees. For deep learning, it can sometimes be difficult to apply appropriately for smaller models and data.1
Unfortunately, the winning approach is only available via a now-dated repo but the idea remains in several other open-source libraries.
One actively maintained library that does some similar marginal approaches, but without differential privacy is Synthetic Data Vault. Copulas is probably the most similar to the NIST winner, using a Copula, or learned multi-variate distribution to recreate the relationships between different variables.
The methods used by the main SDV OSS library vary depending on what parts of the library you're using. If you are using highly sensitive data and have significant privacy leakage concerns, I'd recommend familiarizing yourself with the core methods and determining what fits exactly for your use case.
Whether you are creating your own synthetic data or using SDV, you can use their evaluations to get an idea of how your synthetic data compares to a representative sample of your own data.
In the built-in Data Quality comparisons, SDV offers two important comparison methods:
-
Column Shapes: The statistical similarity within a single column between your real and synthetic data. Stats Speak: comparing marginal distributions per column.
-
Column Pair Trends: The statistical similarity between pairs of columns for your real v. synthetic data. Stats Speak: comparing bivariate distributions of columns)
This is not exactly the 3-way marginals that the NIST team did, but it is a 2-way marginal which can help you find some of those correlations that might be getting mangled by your synthetic data generation.
I have a video walkthrough on these methods with explanations on YouTube
You can use those evaluation scores to tune your generation, either with SDV or with whatever library or self-made workflow you've designed. The goal is not to reach 100% similarity and correlations, but to get close enough to produce similar data without making a copy of your dataset.
This data can be useful for:
- Evaluating new AI vendors (use synthetic first, only real after contract signed)
- Running regular testing, especially AI/ML related testing which might need more realistic data
- Working with Coding Agents or other AI workflows where the accuracy of the data output is not business critical
You might want to check out some other ways to generate data with SDV such as the Constraint Augmented Generator, which is useful if you have specific business relationships and rules, or the HMASynthesizer, which is similar to Copula but for multiple tables.
If for some reason statistical and smaller models don't work for your use case and dummy data is also not appropriate, you'll probably use generative models to create synthetic data. There are safer and less safe ways of doing so, so let's dive in.
Probably Private Generative Models
There are two different workflows in using generative models to generate synthetic data. One of them is actually quite similar to the Faker data above, which is just using prompt engineering with no real data and asking the LLM or VLM to "generate you some example data".
If your prompt is fairly generic and you don't mind that the resulting data is fairly generic, you'll probably end up with data similar to using Faker, but with slightly less effort of thinking through what you are generating.
That's fine; it probably will introduce some data biases, but this can be a quick way to get started with synthetic data.
Note: if you already use a coding assistant, it could help you write out more rigorous approaches, like the statistical modeling above. However, make sure you aren't feeding full sensitive data to it, but instead just describing the statistics of the real data (unless you've approved it with your privacy and legal teams).
The second workflow is actually training or fine-tuning generative models with your data. This can start introducing deep learning memorization problems. It's important to evaluate whether you can train or fine-tune with better privacy protections.
There are many research articles with code repositories available that use differential privacy alongside generative models. Here are a few worth mentioning:
-
Synthetic Text Generation with Differential Privacy: Research from several universities and Microsoft, this is a recent publication with state-of-the-art privacy v utility tradeoffs. There is also a repository available that I hope Microsoft will update/keep updated.
-
Gretel.AI was recently acquired by NVIDIA; however their public archives present a fairly thorough understanding of applying differential privacy to generative model training and fine-tuning. I hope NVIDIA will keep open-sourcing the team's work.
-
Federated Approaches to Synthetic Data Generation demonstrate interesting properties for both local fidelity per node and creating representative but private data across silos. If you have a distributed setup (i.e. with data in different regions/data centers), I recommend looking at this approach first and modifying it for your needs.
-
DPImageBench offers a useful comparison of different privacy-preserving image-producing models. They try several differentially-private diffusion and GAN models and evaluate differences in the training pipeline. Their findings are relevant for anyone using embeddings, as they discover that doing DP and aggregation as part of the embedding process offers stronger privacy guarantees (however, it destroys information, as expected!).
Note: there are many ways to build out generative models other than the most popular GAN or Generative Adversarial Networks. You can use different transformers, diffusion models, flow models and even simple autoencoder setups (either mixed with those other models, or trained for the synthetic data task as part of your DL architecture). Inform yourself on your choices and test a few before deciding which to use for your use case.
If you are training your own models, you want to develop a privacy strategy. Here's a few questions for you and team (and perhaps also your data protection/privacy folks) to review together.
- Are we going to use a third-party synthetic learning platform and train with our real data knowing that there might be privacy leakage?
- Are we equipped to train our own generative models either by fine-tuning open-weight models or training our own models?
- If so, what privacy testing and evaluations can we run to ensure we understand the privacy exposure of our data?
In doing so, you'll likely want to learn about:
- Training and Fine-Tuning Deep Learning with Differential Privacy
- Google's Example of Fine-Tuning for Synthetic Text Generation
- Running Accounting and Auditing for your training/fine-tuning
- PyTorch's Opacus
- Privacy Attacks to run for testing and evaluating
If you are new to training models, I'd give the team extra time to learn how to best set up operations, evaluation and monitoring. Luckily, you'll only need to run these models internally and when you need fresh synthetic data, so it shouldn't be a daily task or deployment.
In reading the latest and greatest in synthetic data production, I also came across a few interesting ideas that I'd like to point out. These aren't "production ready" but are good ideas that I think could offer interesting new research paths for how we do synthetic data.
Novel Ideas worth mentioning
In Differentially Private Small Dataset Release Using Random Projections the authors create new datasets by using least rank methods, which you probably have heard of in today's transformer talk when hearing about LORA fine-tuning.
The approach works like so:
- Take a private dataset and project them into a low-dimensional vector space. This automatically compresses the information and creates some information loss (benefit for privacy).
- Use another algorithm to project them from that "low-rank" space back into the higher-rank/dimensional data space.
- If you choose your parameters right, this offers DP guarantees!
In the paper, they use relatively small tabular datasets compared with today's deep learning methods; however I think the vast amount of people using embeddings could probably find interesting methods to take their current embedding model and add a LORA or lower dimensional latent space projection step to reduce information and encode back into embeddings. If you have already done this or know someone who has, please ping me with the paper/research!
In addition, there are some interesting approaches that are not differential privacy, but similar. "Statistical Privacy" relaxes the differential privacy guarantee, saying that the person querying the database is allowed to learn things about the distribution.
This might provide new pathways for realistic synthetic data generation and translate those to less strict bounds. For teams with "well-behaved" distributions, this could mean much better privacy guarantees for their synthetic data without significant noise or error insertion.
Now you hopefully have found a strategy or two to evaluate, how do you figure out if it's good to use? Let's review some factors to investigate.
How to evaluate your synthetic data
You probably want to develop some evaluation criteria which match your synthetic data use cases. For example, does synthetic data help with data modeling on customer data via a coding assistant? Is it to test out a new AI vendor with customer profiles to build a recommendation system?
Try to define basic outcomes you'd want if you were using the "real" data, as these can help you determine which of the following criteria are most useful and which ones you're willing to have less than perfect scores for:
- Fidelity measures if the data properly matches things like formatting, data types, representative categorical and non-categorical values (i.e. didn't drop a category due to DP). You can also measure more complex correlations by looking into multivariate analysis (as explained in the section on Probably Private Tabular Data). If you have a data quality framework and testing running, you could also run it through that to determine if there are significant errors.
- Utility measures if the data is fit for purpose. This means thinking through some tests you can compare between the real and synthetic data that are use case specific (like, let's say precision/recall if you're doing machine learning training or inference). Basically, you want to know: does it work for what you generated it for and how much information did you lose?
- Privacy measures how re-identifiable your synthetic data is, especially if using it with untrusted or less trusted third-parties. You could run some basic re-identification attempts (use a local LLM to help!) or you can run more complex attacks on your artifacts, inspired by things like MIAs. Did you actually expose an individual that can be reconstructed easily based on your synthetic data? How much effort would it take to de-anonymize your synthetic data?
- Ease of recreation/reuse measures how easily you can generate synthetic data in the future given the tools and workflow you've chosen. This is important to calculate because you can enable easily repeatable and automated synthetic data jobs if you are going to be using this for numerous different use cases. It's fine if you don't measure it the first time, but try to guesstimate how much time and expertise went into the creation and if the data can be reused for any other projects or by other teams. Aim to optimize for repeatable and less expensive initiatives, which will allow synthetic data to become a normal part of internal and external workflows.
You can also create your own metrics and develop them over time. Creating some basic testing and automation and starting small is almost always a good idea.
Tips on getting started
If you're considering using synthetic data for privacy, try to start by defining (roughly) some of the metrics you want to measure and determine a first guess at what is "good enough".
Then test out mixtures of the first two approaches (dummy data and statistics-based methods) and see, is it good enough for what I need? Only if you have highly dimensional and complex data should you use deep learning as an initial approach.
There are some open communities around synthetic data, like OpenSynthetics. I recommend that if you have a complex problem, you can see if there are some domain-specific folks working in synthetic data that understand the state-of-the-art specifics for your use case best and can recommend what you should try first.
As you get a bit more experience, you'll probably form your own opinions and intuition on which of the above approaches work for particular use cases. Trust the process and stay curious. If you want to keep learning about privacy, I hope you'll follow my work!
I'd be very interested to hear how your synthetic data path goes and what use cases you are considering. Feel free to reach out anytime.
If this post helped you, consider subscribing to my newsletter or my YouTube and sharing my work. I also offer advisory and workshops and a new Practical AI Privacy course on topics like security and privacy in AI/ML and personal AI.
-
If doing so, you should probably use state-of-the-art privacy attacks to ensure you are offering the guarantees you think you are with your resulting epsilon and delta values. ↩