Defining Privacy Attacks in AI and ML
Posted on Do 12 Juni 2025 in ml-memorization
In this article series, you've been able to investigate memorization in AI/deep learning systems -- often via interesting attack vectors. In security modeling, it's useful to explicitly define the threats you are defending against, so you can both discuss and address them and compare potential interventions.
Prefer to learn by video? This post is summarized on Probably Private's YouTube.
In this article, you'll walk through two common attack vectors against memorization in AI systems: membership inference and data reconstruction (or exfiltration).
NOTE
This article specifically about privacy attacks related to memorization; but the field of AI security is much larger and broader. Red teaming and other security testing for AI models are a common approach for companies releasing models into production systems. The field of adversarial machine learning explores how AI/ML models can be hacked, tricked and manipulated. It's essential to understand how stochastic systems will behave when attacked or under unexpected conditions to ensure that the deployment is adequately protected or that humans who interact with the system receive appropriate training for handling unexpected or erroneous events.
What is a membership inference attack?
A membership inference attack (MIA) attempts to infer if a person (or particular example) was in the training data or not. It was first named by Shokri et al.'s work in 2016, where the researchers were able to determine which examples were in-group (training data) and which ones were not. The original attack developed a system of shadow models that were similar to the target model. The outputs of these shadow models were used to train another model to discriminate between in-training and out-of-training examples.
Since the initial attack definition, there have been a variety of improvements -- creating targeted variants to adaptively expose particular training data points or variants that attack correlated groups of data points. Several related attacks can expose sensitive attributes of individuals by revealing which subpopulations they belong to or teach attackers about overall training data populations and their qualities, which could be exploited to perform better MIAs.
Why does this work? If a model memorizes a particular example, it should return large confidence on that data point compared to similar data points it hasn't seen. If these examples are infrequent or rare (i.e. in the long tail), then these examples are overexposed compared to other examples, which can "hide in the crowd". As you already learned, larger and more accurate models display this problem more often than smaller and less accurate models.
To illustrate this, researchers worked on training multiple models on different splits of data. They then found ways to show the inlier versus the outlier-ness of particular examples by showing how the model performed on these if it processed them as part of the training data or not. For outlier examples, if they weren't in the training data, then the model performed quite poorly on them. Even for inliers, if the example was more complex (i.e. harder to learn in one training round) then the loss (i.e. accuracy) on that example leaked more information than if it was easy to learn.
This figure shows a view of the model's prediction accuracy via cross-entropy loss when comparing images in the training dataset with images out of the training dataset. As a quick reminder, cross-entropy is an accurate way to measure performance for a classification model, where it calculates how far the resulting prediction is from the true label.
If you were performing a privacy attack, you'd want to find a way to separate the member distributions in red from the non-member distributions in blue. For outliers, this is much easier! And for more complex examples that are "harder to learn" this is also easier.1
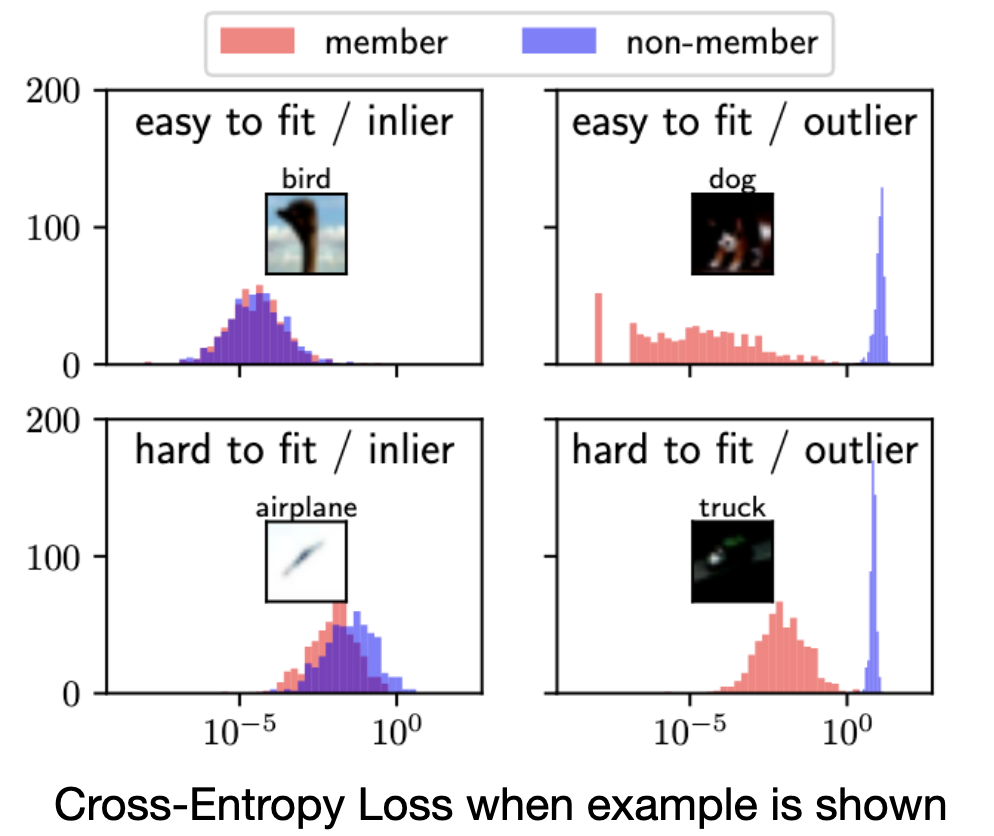
This problem is exacerbated when model size grows and when those models are trained with datasets where one large data collection, such as ImageNet, is used to pull both testing and training data. Unfortunately, as shown in the previous article, these datasets often have duplicates or near-duplicates and this ends up leaking additional information that incentivizes memorization. As you can imagine, this doesn't just affect image datasets -- the internet is full of near duplicate or exact duplicate text and other content forms (i.e. video/audio/etc).
This figure plots different model architectures, where the y-axis shows accurate attack successes and the x-axis shows the model's performance on the holdout test examples. As you've already learned throughout this series, performing well on a test-dataset from a long-tail distribution and many outliers likely requires some element of memorization.2
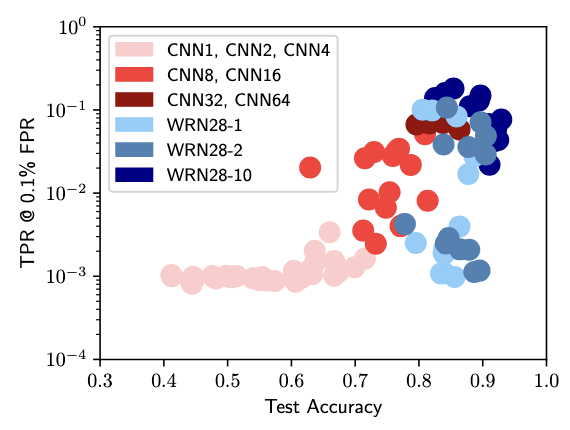
Combining these two pieces of knowledge (i.e. the likelihood that an example is an outlier and the confidence in the model to guess it properly) is a good way to infer this membership.
Both of the above figures come from the Likelihood Ratio Attack (Carlini et al., 2022), which is specifically designed to minimize false positives (i.e. alerting that something is a member when it is not).3
The steps to perform this attack are as follows:
-
Sample from a dataset similar to the dataset you think was used by the model you want to attack (target model). Create data subsets, so each of the examples in the dataset are seen (and "not seen") by the models you will train. These are called shadow models, because they act as a stand-in for the target model.
-
Train your shadow models keeping track of which models have seen which examples. This creates sets of in- and out-shadow models, where the in-models have seen the example and the out-models have not. Try to match the model architecture and task of your target model as accurately as possible for best results.
-
Measure the model outputs (i.e. prediction accuracy / loss) on a particular example and scale that loss by using a logit function. Repeat steps 1-3 numerous times and try to cover a large swath of the the training data, with a variety of classes and examples. Store the scaled losses with notes on the example they were measured with and whether the model had seen the example or not (in-versus-out shadow model).4
-
After many training iterations and when you representative set of scaled losses on a variety of examples, analyze the scaled losses of the in-versus-out shadow models. You will hopefully have two distributions that don't completely overlap. Similar to the other CE-loss distributions you saw above, you want to try to separate these two distributions to be able to tell if something is in the training data or not based on the loss.
-
Query the target model with the target example. Scale the returned prediction and use probability theory to figure out if the example comes from the "in-training" or "out-of-training" distributions.
There are additional suggestions and improvements to this attack based on model architecture, datasets and that you can review in the paper and the related code repository.
Related variants of these attacks can also directly expose the training data by guessing close to the exposed data point and optimizing the input until it reaches the memorized input. This can show what data is in the training and what data isn't.
If I can learn something about you by knowing you were in the training data, then I can use this information for my own benefit. For example, if I know you have a particular disease, or visit a certain website often or if I know your immigration status or income level because your data was in a model that only represents people like that -- then this is all extra information I get from a membership inference attack.
These attack vectors overlap with data reconstruction attacks, because if I know you are in the training data, I can also attempt to extract your data directly.
What is a data reconstruction attack?
Data reconstruction attacks attempt to discover, reconstruct and exfiltrate the training data. As you might guess, this works better if the data was memorized!
If combined with membership inference attacks, these two attacks can first determine which data probably exists in the model, and then either recreate that data and test its veracity or to attempt to exfiltrate the memorized data from the model itself.
As you learned about in the article on repetition as a source of memorization, this can mean a full exfiltration of heavily repeated examples, which is easy to do if the example is common enough and has been memorized. In a way, this is expected data reconstruction, where we want to learn common information (i.e. a widely known text or celebrity face).
And as you read in the article about novelty as a source of memorization, these attacks can also directly expose less frequent examples, particularly outliers or infrequent examples. This might mean accidentally learning personal text data, like social security numbers, credit card numbers and home addresses that can then be extracted either by querying the model itself, or by a targeted attack. There are variants of these attacks that use both "white box" (i.e. direct testing of the model with a view of the model's internal state) and "black box" (i.e. API access) methods.
A related but contested variation of data reconstruction invokes paraphrased information. Here, the model outputs are compared with their training data to discover partial verbatim and paraphrased content. For visual content, these "paraphrasing" attacks can look at portions of the image or video and determine if particular features come from particular training data examples.5
For example, the below images are not exact duplicates, but are clearly near-duplicates. For each pair, the left images are from the training data, and the right images are generated by prompting Midjourney with the training data caption. This research from Webster (2023) unveiled efficient and accurate ways to reconstruct training data from diffusion models.

For content creators or artists, this type of attack might be important if their content is particularly popular or interesting for particular AI/LLM audiences.
Let's walk through these two main attack vectors and their variations in real-world threats where an organization or individual might be concerned about their information being memorized.
Threat: Outputting copyright material or images
One obvious initial threat is explicitly copying copyrighted content and outputting it with little or no variation. This has already sparked several prominent lawsuits, such as The New York Times vs. OpenAI, where ChatGPT outputs verbatim copies of popular New York Times articles without attribution.
Researchers have also been actively reproducing these attacks in visual images, where copyrighted characters or visuals can be easily reproduced, even without directly invoking the name. For example, typing "Gotham, Superhero" produces copies of Batman.

This affects other mediums, such as music and video content as those AI models become easier to use and more widely available. There have already been highly publicized examples of voice and video-cloning use for criminal activities.
For organizations and persons whose income or existence relies primarily on producing and licensing copyrighted content, this is certainly a very serious threat -- one that deserves attention and discussion in a public forum.
Threat: Violating someone's privacy by directly outputting their information
One drastic case is the either intentional or unintentional release of a person's sensitive information. This information could be their face, their words taken out of context, their contact information or other information they would rather not share via a machine learning model.
This is documented in research, where ChatGPT directly output personal contact information, where StableDiffusion can reproduce a person's face and where models trained on sensitive keyboard data output that information.
There is currently no required reporting from companies providing machine learning models to test, audit or verify this behavior. A more comprehensive understanding could be achieved by institutionalizing privacy auditing and reporting for deep learning models which could be standardized and enforced by a regulatory body. This could accompany other monitoring and testing for privacy right related to hallucination, like when a model repeats outdated and incorrect information or hallucinates things that never happened.
For well-known persons, this threat extends to uses like DeepFakes or other clones, where their likeness is used in ways that they did not consent to, such as the rise of DeepFake-Pornography and DeepFake-Propaganda. Combining these attacks with other software like "face transfer" makes these violations easier to do with enough examples of the person's likeness/voice (i.e. this could be performed by a person close to the person, or a person with access to enough photo or video materials of the person).
Threat: Learning if someone's data is in a model or if someone is in a particular population
Membership Inference Attacks can reveal information about someone's participation in a particular service, population or activity. That might seem harmless at first -- who cares if someone knows that OpenAI scraped my data?
For LLMs, it's not as relevant, but what about models that specifically target a certain population: like a model built to evaluate people with a disease for medical treatment, people with a certain income for advertising or credit evaluation or people with a particular political view for political ads or border control? These models exist, and membership in those models would expose related sensitive information that people likely don't want to share out of context.
Related attacks on subpopulations rather than individuals can also reveal information about the subpopulation that expose that group's sensitive attributes. Similar to the Cambridge Analytica attacks, where "harmless" information about liking Facebook Pages provided enough information to expose related sensitive attributes like gender, political affiliation, drug use and sexual preferences.
Threat: Stealing someone's work without attribution or compensation
Another real-world problem for organizations is directly repeating someone's work without appropriate attribution. For example, security researchers found private repository code from several FAANG-companies available in Copilot. The memorized code from the repositories was accessed when those repositories was public, but since then the repositories have been changed to private and the models haven't been updated.
This isn't the same as the copyright issue, because there is quite a bit of content that isn't explicitly under copyright, but is intended to create awareness, wealth and recognition for the original creator. For example, in creative and software communities, there are popular licenses that require attribution or even specify under what conditions the work can be reused or remixed. When the author, coder, artist is cited by someone who remixes or reuses their work, this creates more awareness, building their audience or giving them new opportunities.
Because of this, there's been increased awareness of GenerativeAI in artist communities, who want their art to be used by AI systems, but who would like attribution, or compensation, or both.
In a recent example that overlaps with copyright protection, artists released a "silent" album to protest the UK's proposal to not enforce copyright for AI-generated work. There have been many such protests over the past 5 years.
Threat: Overexposing certain populations to the above attacks
As you learned in the how it works (novel examples) article, some examples are more beneficial to memorize for the model's evaluation scores (i.e. accuracy on related difficult examples). This means these examples are also memorized at a higher frequency than other examples.
This might seem innocuous, but if you investigate these data distributions, you'll find that these underrepresented groups in those populations are overexposed when it comes to privacy. Research from Bagdasaryan and Shmatikov proved that models trained with differential privacy did poorly on fairness metrics across diverse groups. For example, privacy-respecting models performed worse on sentiment analysis on African-American English versus a "Standard" American English dataset. In the same research, privacy-respecting models misclassified gender for dark-skinned faces more frequently than light-skinned faces.
This demonstrates how increases in model fairness and accuracy for subpopulations is directly related to specific memorization of individuals whose data comes from that subpopulation. Put differently, certain persons in an underrepresented group give up their privacy in exchange for better model accuracy on "data like them". This overexposes individuals in this group when compared with other persons from a majority population in the dataset who can "hide in the crowd".
In larger machine learning datasets, this problem is exacerbated due to human biases in labels, where a white man might be labeled "man" and a black woman is labeled "black woman". This labeling problem occurs any time a subpopulation assumes that they represent the general population. This label bias exacerbates the memorization problem, because each label must be learned separately, and many of these "non-majority" labels will end up in the long-tail and be more prone to memorization.
Shokri et al. investigated this issue when looking at explanations for deep learning systems and found that data reconstruction attacks worked more easily on minority populations when using model explanations on the same or similar examples. Chang and Shokri formalized this privacy issue for minority populations in other works, proving that minority populations are at greater privacy risk, especially when fair algorithm and model design do not take privacy into account.
Threat: Exposing critical knowledge from training data unintentionally
Another memorization issue is the ability for these systems to memorize corporate secrets, important legal contracts or otherwise confidential information. Because the model is not incentivized to understand the difference between text, photos or other media that should be learned versus other material that shouldn't, this creates a significant problem for organizations with confidential material they'd like to use for machine learning.
For example, after the launch of ChatGPT-3.5, Amazon's legal department found text snippets of text that shared internal corporate secrets in the chat model's responses.
This can also unintentionally happen when building systems with access to such documents -- even if they haven't been trained on that data. These exposures have little to do with AI memorization and more to do with lack of privacy and security understanding in Retrieval Augmented Generation system design.
Should you be concerned?
As you've seen thus far, the only reason to be worried that sensitive data will be stored in the model is if you are training the model on data that you don't want explicitly memorized. If you don't train with copyrighted, licensed or person-related data, these attacks aren't a threat.
If you are using corporate proprietary or internal data and you are only using the model internally, this probably isn't an issue, so long as the model outputs are also considered "for internal use only". As usual, talk with your legal and privacy teams to clarify.
If teams or individuals are training their own models (i.e. personal or collaborative-based models) and they all consent to this training and co-own this model, this might not be a problem if the data is available for use across the entire company. In my experience, those teams should discuss and be aware of memorization, but they presumably enthusiastically consent to the use and development.
So really you should only be concerned about this phenomenon if you are training model that:
- use people's data without their enthusiastic consent and knowledge
- is used or deployed in new contexts (i.e. for a new purpose / in the public sphere / for something that those people wouldn't agree to)
- doesn't address the privacy/content implications as part of model design and development
You might think: that's got to be a TINY percentage of models, but my industry experience can confirm that this is a non-trivial amount of AI systems, including many of the LLMs, Code Assistants and AI Agents.
You might also wondering about the implications if you use potentially at-risk models but don't train them. This puts you in a difficult position of not influencing the model development but potentially being exposed to the same threats above. Being aware of these threats is a good step when evaluating what systems to integrate for what tasks, and there will be a future article in this series on addressing exactly this situation.
Now that you've identified the biggest potential threats, let's begin investigating ways to address these threats. In the following articles, you'll learn about:
- Software- and system-based interventions, like output filtering and system prompts
- Fine-tuning guardrails
- Machine unlearning or intentional "forgetting"
- Differential privacy in training and fine-tuning
- Evaluating and auditing privacy metrics in deep learning systems
- Evaluating AI systems and their threats as a third-party user
- Pruning and distillation for information reduction
- Different types of models that could offer explicit and enthusiastic consent and public participation
Have a burning question or idea related to these topics, or want to share new threats and ideas? Please feel free to reach out via email or LinkedIn.
Acknowledgements: I would like to thank Vicki Boykis and Damien Desfontaines for their feedback, corrections and thoughts on this series. Their input greatly contributed to improvements in my thinking and writing. Any mistakes, typos, inaccuracies or controversial opinions are my own.
-
These histograms show unscaled cross-entropy loss (CE-loss) collected from 1024 models that were trained with training data produced by leaving samples in/out. The CE-loss per example was collected to visually show the behavior of different types of examples and classes in the underlying training distributions and subsequent models. ↩
-
The y-axis is logarithmic and shows the attack accuracy when holding for a high performance rate (False Positive Rate of 0.1). This is done as part of their attack design, where they aim to create more rigorous standards for MIA measurement to just focus on attacks that don't guess membership incorrectly. ↩
-
A fun piece of information from this research is that the attack's success can be measured by looking at the model generalization gaps. This connects with what you've learned so far on evaluation metrics and the generalization gap as an indicator for memorization. In general, they find that models that are more accurate and larger are easier to attack, which aligns with what you've already learned thus far. ↩
-
There are numerous tips in the paper and an openly available implementation on GitHub that shows how to parallelize this and how many models and data splits are efficient to develop the distributions needed for the attack. ↩
-
For example, when the website "this person does not exist" launched, researchers were quick to find "AI generated people" who actually represented faces in commonly used public face datasets. See Webster et al., This Person (Probably) Exists, 2021. ↩