How memorization happens: Repetition
Posted on Di 03 Dezember 2024 in ml-memorization
In this article in the deep learning memorization series, you'll learn how one part of memorization happens -- highly repeated data from the "head" of the long-tailed distribution.
Prefer to learn by video? This post is summarized on Probably Private's YouTube.
Recall from the data collection article that some examples are overrepresented in the dataset. They live in the "head" area and might be duplicated and show cultural and societal biases based on the collection methods. You learned in the last article how training steps work and how data is sampled, along with the overriding cultural focus on accuracy above everything else. In this article, you'll evaluate how wanting to score highly in accuracy with an unevenly distributed dataset creates the first problem with memorization: memorizing common examples.
To begin the analysis, you'll first explore how a simple machine learning system works. To begin, you'll look at random forests as a popular classical baseline, and then review how a deep learning system works. If you're already familiar with these models, you can skip ahead to sequence-based deep learning.
Simple Machine Learning Model
Machine learning is the task of determining if computers (via software) can use patterns to make inferences or decisions about an example. Machine learning models are used to automate or expedite tasks, like identifying and sorting spam messages, or offer assistance in making a particular decision, like if a patient should undergo additional screening for a disease. Machine learning models learn patterns and condense information based on historical data.
In today's machine learning, you usually choose what software and algorithm you want to use before you begin the training process using your training and test data. As you learned in the encodings and embeddings article, the data is transformed into mathematical form (vectors or matrices) in order to train and also predict.
For simple machine learning models, you first choose an algorithm. A good set of examples for classic algorithm choices are shown in scikit-learn's overview. Broadly, these choices depend on things like your data size and structure and the task you want to solve. For example, you might want to predict a number or trend, like in forecasting, or classify something, like finding all positive product reviews from a series of texts.
One popular choice due to its simplicity and performance tradeoff is random forests, which is an ensemble of decision trees. You can use random forests for many classification tasks, where you want to assign an outcome or label to an incoming piece of data. Because random forests are built out of decision trees, let's review a decision tree first.
In a decision tree, you want the algorithm to determine useful splits in the data based on particular attributes. Ideally, these attributes split the data into fairly homogenous buckets. For example, if you are trying to decide whether someone has a particular illness, you'd want to end up with a tree that splits perfectly the people who have the disease from those who don't by using information encoded into the data. An example tree could look something like this:
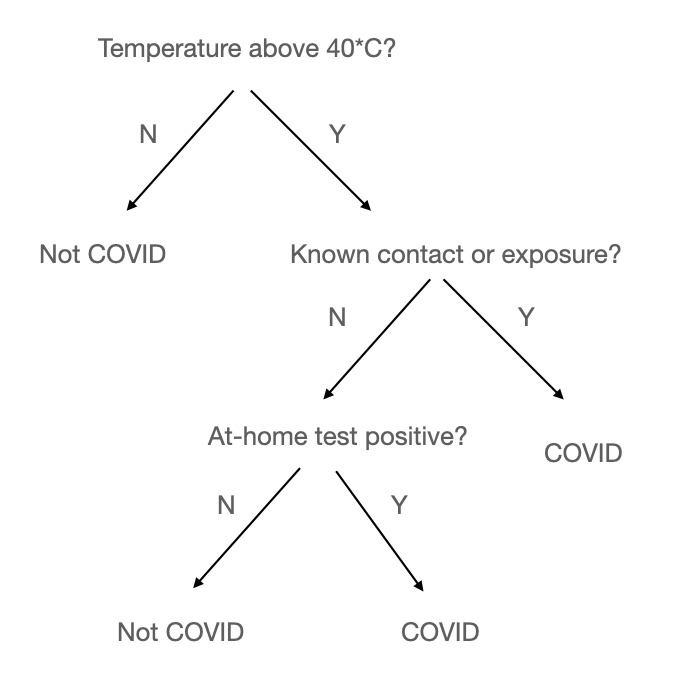
This is an oversimplified toy example, but it demonstrates the basic structure of a decision tree, where particular pieces of information are used to create hierarchical data splits based on particular attributes.
A random forest is a collection of such decision trees, hence why it's called a forest. When you train a random forest, you specify the number of trees to train. Each tree usually starts with separate samples of the training data so they don't overlap, which results in different splits for the trees.1 If you train many trees, some will likely be quite similar and some will be heavily biased based on their sample of data. With enough different trees, you can create robust performance. Because each tree gets a vote, the majority vote becomes the most likely class or label.
Once you have a trained random forest, you can run inference (aka. prediction) tasks with your trained model. Your model is now an artifact that contains information and instructions for how to take a prepared piece of data and output a prediction (or a series of predictions with different likelihoods).
To get a prediction, you send an example like how the training examples were processed -- but this time without the label or result. The model returns the particular outcome or classification label, usually with an indication of the confidence in that prediction. In a random forest, the model asks all trees to make a prediction and each tree votes on the outcome. The confidence is essentially the voting distribution (i.e. 30% trees say not infected, 70% trees say infected). It's your job as the human to figure out if the model is making the correct decision.
When you take a simple model, like a random forest, you can often also reverse engineer the model's decision. This is useful for determining if you trust the decision. For example, you can look at which trees voted for the majority decision and investigate what branches in those trees contributed to that decision. This process is referred to as the interpretability or explainability of the model. When a model is simple, like with random forests, you can use your human understanding to evaluate how trustworthy and accurate you find the prediction. This is demonstrated in "human in the loop" systems, where a human can use a machine learning model and the interpretation of the model's prediction to make an informed decision.
Now that you've investigated a simple machine learning model at a high level, let's take a look at how it compares with a deep learning model.
Deep Learning Model
In a deep learning model, at the model selection level, you don't make one algorithm choice, but instead many choices. Because a deep learning model often consists of many layers of functions which interconnect, you are building a model architecture rather than one algorithm choice. Researchers try out new architectures, adding new types of layers or changing the layers and changing the algorithms within those layers to seek performance improvements or innovative approaches.
Within industry, you are usually just implementing other people's architectures that you know work well for the type of problem you are solving. For example, many of today's LLMs use a Transformer architecture, which is a fairly complex deep learning architecture that uses an attention mechanism. Attention mechanisms were first introduced by Google researchers in 2017 in a famous paper called Attention Is All You Need. GPT models are a type of transformer, with small changes in how certain parts of the encoder (to "read" the incoming text) and decoder (to "write" the response) work. For an illustrated and deeper dive into transformers, check out the Illustrated Transformer.
In much of today's deep learning, unless you are at a large company with an extensive machine learning research team or a machine learning-based startup focused on research, you are likely using someone else's model. This could mean that you are using an OpenAI API call, where you are also not even hosting the model, or it could mean you first download and use someone else's model and deploy it on your own infrastructure.
There are also ways to download a model that someone else first trained and train it further. This is called transfer learning or fine-tuning. When you do so, you take a model trained on a task and train it further, to better align with your particular data or use case. If you don't have enough of your own data to train, there is increasing use of large scale language models (LLMs) to assist in building out robust training examples for model distillation tasks. With model distillation your goal is to actually build a smaller model that performs well on your particular use case, hence "distilling" the information from the larger model (see: Spacy's human-in-the-loop distillation).
In deep learning, you are often dealing with data and tasks that aren't suited for simpler machine learning models -- like generating photos, videos, audio, text or translating those from one medium to another. Deep learning is what powers Generative AI, what allows for text-to-speech or speech-to-text, and what is used for computer vision tasks, like facial recognition or "self-driving" cars. The complexity of such tasks and the data size make deep learning more performant than simple machine learning models.
For training deep learning models, as you learned in the training article, the entire training dataset is input into the model multiple times. In today's largest models the training set is seen tens of thousands of times by extremely large models. These models are called over- or hyperparameterized because they actually have more parameters--weights, biases and other parameters that the functions of the network might use--than there are training data points. You might have heard about 1 trillion parameter models, and yet these models were trained with less than 1 trillion pieces of unique data.
Compared with the earlier decision tree and random forest example, a deep learning model is much more difficult to interpret. Especially as the layer complexity and depth grows, as it does with large deep learning models, it's difficult to look at the activations of the nodes and make any sense of what is happening in a way that humans can understand. Despite the difficulty in working on human-interpretable understanding of deep learning, it hasn't stopped researchers from trying to peek inside these networks to see what is happening.
LIME or Local Interpretable Machine Learning Explanations investigated if small changes in inputs could expose and locate deep learning decision boundaries. To envision how this works, first think of a 3-dimensional space, where inputs are represented as coordinates. Then, imagine planes marking boundaries between those points that help you determine whether the point belongs to one group or another. In reality, these models are extremely high-dimensional and non-linear in nature, meaning it works a bit differently than you just imagined, but LIME worked by changing the coordinates to figure out where these boundaries were and then used that information to say this part of the image or text is why it was classified with this label. Since a neural network is not a simple linear equation, finding these boundaries can be quite difficult, but it was an interesting first step.
Been Kim's work brought the field of deep learning interpretability to a new level. In her work at DeepMind, she investigates how hidden layers (the layers between the first and last one) can create intermediary representations which map much closer to interpretable patterns for humans. Her seminal contribution of "Testing with Concept Activation Vectors" (TCAV) created a way to try to use human interpretability approaches to understand deep learning, not the other way around.
Deep learning is a large area of machine learning, with many different model types. To focus our attention on particularly useful areas of deep learning to explore memorization, you'll start with sequential deep learning models, where you want to predict what happens next when presented with a sequence. As you might already know, this is the deep learning that powers today's text-based Generative AI, like OpenAI's ChatGPT and Google's Gemini.
Sequential Deep Learning Models
For many years, it was difficult to do language-based deep learning. Deep learning computer vision models were well into production by the time word embeddings made language deep learning possible. This is because of the size and complexity of language, which has much wider ranges and of course, also multiple languages that one could use. It was also because there wasn't a good way to do performant sequence-based models for a long time.
As recently as 2018, generative text models would quickly devolve into babble or change topics midstream. What significantly shifted the field are two inventions: the attention mechanism and the large context window. Let's walk through both at a high-level to appreciate what they were able to bring to generative text.
The attention mechanism creates specific parts of the deep learning model which hold "attention" on links between elements of the sequence. This helps create a web of references, which greatly improves the ability to produce meaningful language.
These attention heads are both on the encoder ("reading what is coming in") and the decoder ("writing what is going out") with an additional one between the encoder and decoder. These attention heads can hold input or output embeddings within a sequence that are calculated as more significant or useful, depending on the task at hand and the training data.
Let's look at an early example of attention from the original Google paper. In this view you can see two of the attention head weights of each token when looking at another token, which reflects what those weights have "learned" are links between sequential inputs.
 An example of attention head links
An example of attention head links
In this example, the entity (or subject) linkage and attribution was learned by this attention head, allowing "law" and "its" to be linked. The attention also links to application, tying law and application together via the pronoun it.
For early text-based transformers, attention mechanisms could only be used on a subset of the overall sequence due to memory and compute limitations, often limited to under 2000 tokens. This means that the prompt (initial instructions) as well as the ongoing generative text could only be given attention up to that context window limit. This limit bounded the length of meaningful generative text - particularly when using transformers for longer generative text tasks, such as summarization, chat, or search and information retrieval.
To address these use cases, model developers like OpenAI increased the context window size of the attention mechanism, which also increased the hardware memory requirements and computational cost of the models. This means that you could often hold entire conversations or chapters of books in the context window, creating the ability to stay on task, but also giving the model extra context to ensure that the important tokens and ideas are always available. Today's LLM context windows are often 128,000 tokens or longer. Compare that to Shakespeare's Hamlet, which is just over 30,000 words.
I often describe context windows as the model's RAM (Random Access Memory). RAM allows computers to easily grab recently used data to accelerate computations or loading times. When you encode text, that might be bytes, characters or words, so these context window sizes could roughly translate that a model has more than 50,000 words in RAM. How does it process what word comes next?
To oversimplify, you can think about all of the possible words and tokens as different points in 3D space, as you did when looking at decision space. The attention mechanism and context window might already have highlighted some of these points as more important or more relevant to the model - which also means points near them become more relevant.
The model has been trained first on many sequences in order, and gotten information about how tokens come together. During pretraining (which is what first happens with today's language models), it updates many hidden layers of weights to "learn" how the input corpus works and what sequences of tokens are common or uncommon.
The embedding information of each token also carries added information about tokens that are similar, near each other, or tokens that have a particular distance from one another which shows their relationship, as you learned when reviewing Word2Vec.
If the model has learned enough about language and the input has enough context (i.e. via the context window RAM), it can create sensical combinations that are on topic by also combining its output as part of its sequencing (i.e. writing word-by-word and continuing to compute what a useful next series of tokens might be).2
In a situation where you have: Why did the chicken ..., you can probably guess the next word, as it's a common phrase. In a deep learning sequence-based model, the network calculates which of all of the possible next steps are most relevant using the steps it has already seen and already generated. Usually the highest probability next step is chosen, but there might be clever ways to see the best sequences that aren't just exactly the next most probable step. For example, you can predict several different sequences using several of the next most probable steps and calculate the probability over the entire sequence, not just the exact next step.3
In statistics (and in deep learning), this relates to the log-perplexity of the next sequence. This is a useful comparison for the final stages of the decoder in a transformer, which should take all of the calculations to this point in time (including calculations from the context window) and run it through several final deep learning layers. This ends with a Softmax function which takes the prior layer inputs and translates them into a probability distribution for the different tokens. Depending on the strategy, either the most likely token or some combination of most likely tokens will be chosen.
How does this affect the problem of memorization? Let's put together what you've learned thus far to see the bigger picture.
Repetition Begets Memorization in Deep Learning
Let's investigate a few facts that you now know:
- Scraped, collected datasets have a section of examples that are repeated often and are much more common.
- During model training, the model will be optimized on these examples hundreds, if not thousands of times.
- Sequential language modeling must choose the best answer with one word missing. It also can hold a massive amount of words in memory to access at any time. These words build weights and connections in the network itself.
- The model and model developers are incentivized to score well on the "test" and are penalized (error and loss) when they fail. The training rounds should explicitly use this penalty to improve.
- The "best" model wins, regardless of interpretability or if cheating has occurred.
There are both mathematical and human incentives to produce models that memorize common text, particularly if that text will be in the testing dataset and if that text has been seen multiple times during training. Even more so if that text is presumed to be known by the users of the model at a later stage.
Google researchers proved exactly this fact in 2018, when they released a paper called The Secret Sharer. Carlini et al. stated in the paper, "unintended memorization is a persistent, hard-to-avoid issue that can have serious consequences". They were able to demonstrate the extraction of both common and more rare training examples that had been processed multiple times in the training rounds.
In a later piece of research by Carlini et al., they were able to show that model size impacts the memorization, and that repeated examples are especially prone to memorization. They estimated that a minimum lower bound of 1% of the training data is memorized, but an unknown upper bound.
In some of their experiments, they were able to extract more than 32% of the text that was included in at least 100 training data examples, sometimes not the full text token-by-token, but enough to recognize and match the text. Their testing was on much smaller models than today's models, as they used GPT-Neo and GPT-J with 6B parameters. In comparison, it is believed that GPT-4 has 1800B parameters.
Here is a comparison chart linking model size to text memorization by showing a few examples they were able to extract:
This memorization within deep learning can be also observed in the attribute inference and membership inference attacks where an attacker can find and extract common properties of the underlying training data population or reveal if a particular example was in the training data based on the model response. Particularly interesting is the work This Person Probably Exists on deriving attributes from a computer vision model that was trained on the CELEB A dataset - a dataset consisting primarily of celebrity faces.
Let's see if this type of behavior is easy to evoke using online freely-available tools.
Easy Examples
With almost any generative tool, you can easily create images of particular brands, faces and common images, like this version of Angela Merkel, created on Stable Diffusion Web.

Let's see if we can also reproduce this type of memorization using ChatGPT (free version).
An initial prompt of "Can you tell me some popular children's authors?" gave me a list starting with Dr. Seuss, so I asked to know about a book from Dr. Seuss and was told about Green Eggs and Ham and how it had good rhymes. I asked the ChatGPT service to show me some of the writing and it did so with the opening stanzas: Would you eat them in a box? Would you eat them with a fox? (and a few more lines).
Then I asked:
 Reading Dr. Seuss with ChatGPT Memorization
Reading Dr. Seuss with ChatGPT Memorization
And got a not quite perfect but pretty close continuation of the entire book (the response was more than 600 words and spaced in the appropriate stanzas).
ChatGPT can also easily reproduce code and related topics, like the Zen of Python:
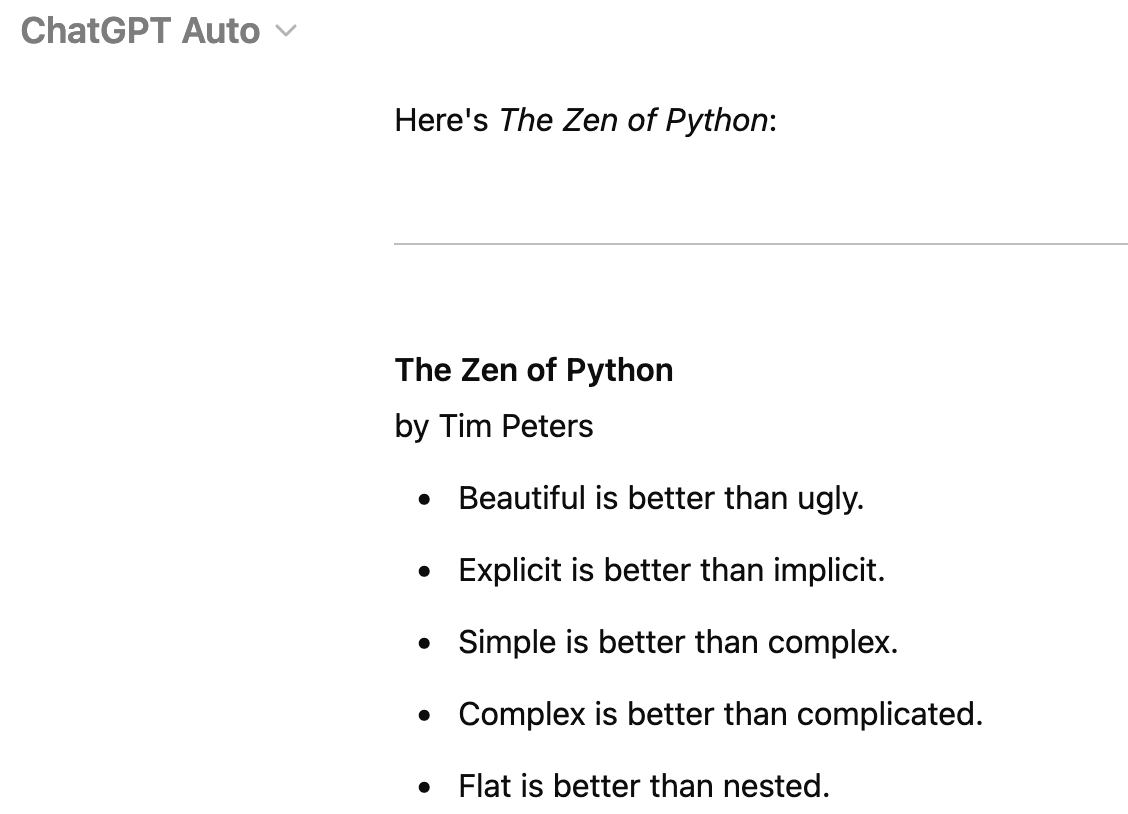 The Zen of Python from ChatGPT Memorization
The Zen of Python from ChatGPT Memorization
You might be thinking, ah, well this is exactly the goal. If you train a large model on a bunch of repetitive things, then of course it can also repeat them. You're correct! It is indeed both expected, anticipated and empirically true!
It just might not be the outcome that Dr. Seuss's family expected, or at the scale that any popular artists, authors, creators, musicians and coders imagined. It can be both expected and yet have unanticipated and unintended secondary effects. It can be both desirable given the specific machine learning task but not well thought through in terms of cultural, societal and personal impact.
Unfortunately this is not also the only way that memorization occurs. In the next article, you'll review how unique and novel examples also end up memorized. Stay tuned!
I'm very open to feedback (positive, neutral or critical), questions (there are no stupid questions!) and creative re-use of this content. If you have any of those, please share it with me! This helps keep me inspired and writing. :)
Acknowledgements: I would like to thank Vicki Boykis, Damien Desfontaines and Yann Dupis for their feedback, corrections and thoughts on this series. Their input greatly contributed to improvements in my thinking and writing. Any mistakes, typos, inaccuracies or controversial opinions are my own.
-
Random forests usually use statistical methods like bootstrapping and bootstrap aggregation, or bagging. I encourage you to dive into the links to learn more, but on a high level you can think of these as statistics-informed sampling methods, which allow creation of samples that aim to represent the dataset or populations within the dataset. This may also increase the dataset size by resampling from a subset of data. ↩
-
For LLMs today, there is usually also a second round of deep learning training after the initial language model learning, which originally was based on reinforcement learning and called reinforcement learning with human feedback (RLHF). This usually involved chat style prompts and then data workers who were paid very little money to both write their own responses as if they were the AI assistant, but also to rate which response was best out of a variety of responses. Now there are several approaches for this type of instruction training and tuning, which are not always reinforcement learning-based, but instead use traditional deep learning approaches by incorporating human preference information into the loss function. ↩
-
There has been some success at using approaches like beam search to compare potential sequence options and calculate their probability or their preference (when using human input to determine best responses). This creates more options and potential variety in responses. ↩