How memorization happens: Novelty
Posted on Mo 09 Dezember 2024 in ml-memorization
So far in this series on memorization in deep learning, you've learned how massively repeated text and images incentivize training data memorization, but that's not the only training data that machine learning models memorize. Let's take a look at another proven memorization: novel examples.
Prefer to learn by video? This post is summarized on Probably Private's YouTube.
As you learned in the evaluation article, the chance of pulling a rare or novel example from the tail is fairly high, given that the tail is long and makes up the majority of the distribution. If you are training multiple models and evaluating them against one another based on test performance, there is a good chance that the best performing model will process more of the novel examples that also exist in the test dataset.
Vitaly Feldman, previously of Google Brain, now at Apple Research, initially studied this phenomena in 2019 in his paper Does learning require memorization? A Short Story about a Long Tail. Let's walk through the important parts of the paper together.
In the first example of the paper, the learning algorithm will learn to differentiate two groups in a binomial population. This is a small toy example to easily define how a machine learning model should minimize the learning error. This example is an oversimplification of typical machine learning problems, but Feldman uses it to extrapolate learnings to more complex examples.
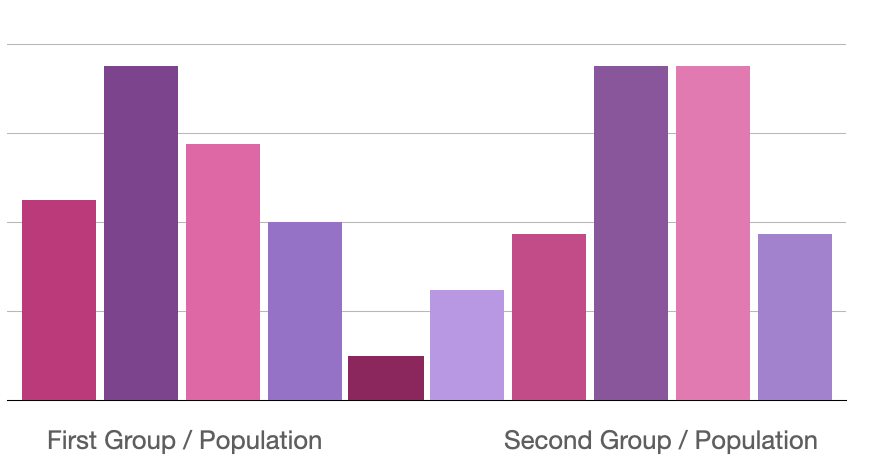
In order to show how memorization happens, the paper then defines memorization mathematically. To do so, Feldman defines memorization by comparing two models. One has seen a particular example and the other has not. The difference between the two models demonstrates whether that point contributes significantly to memorization or not. This is a "leave one out" principle -- which can be used to test memorized training examples in real systems.
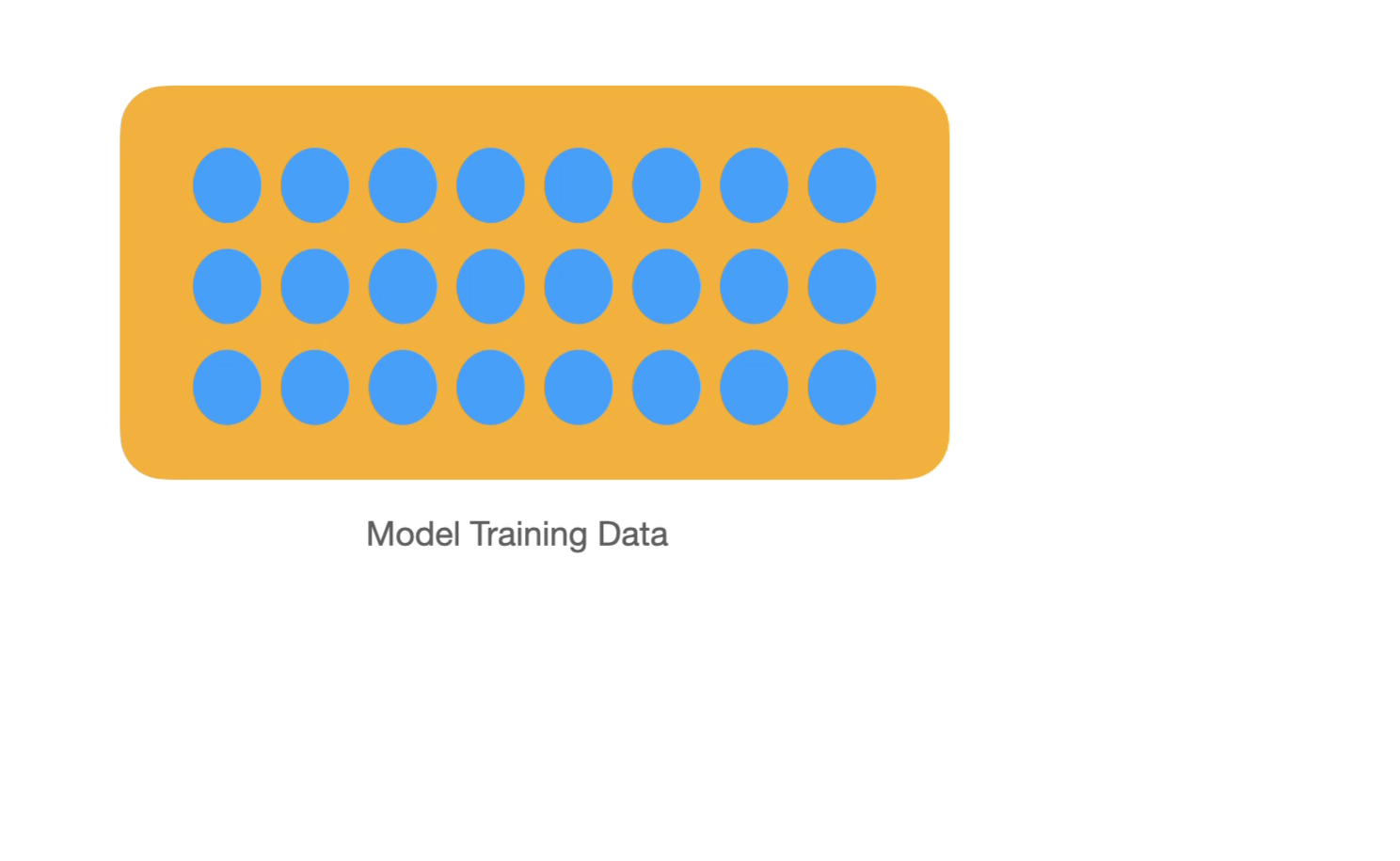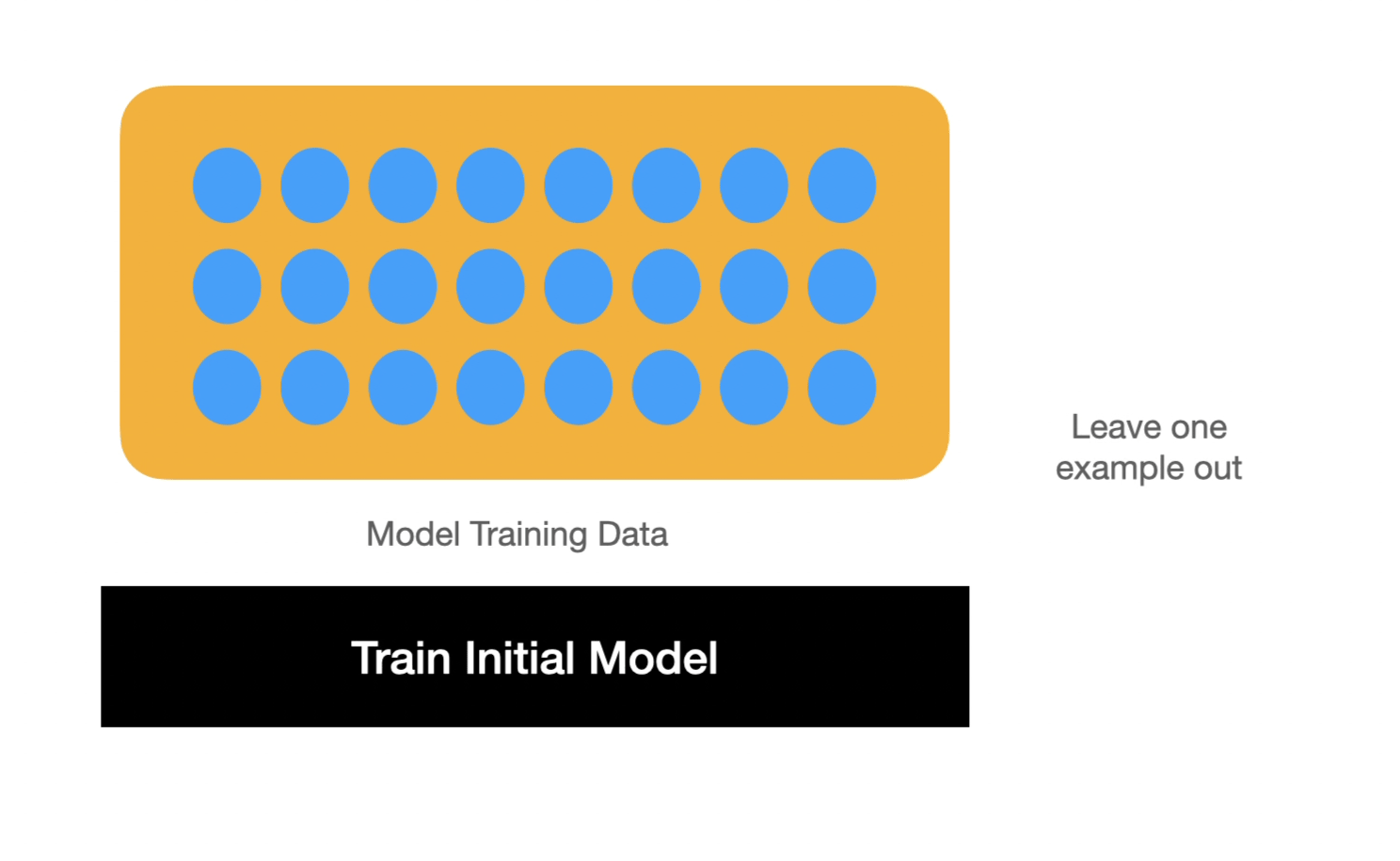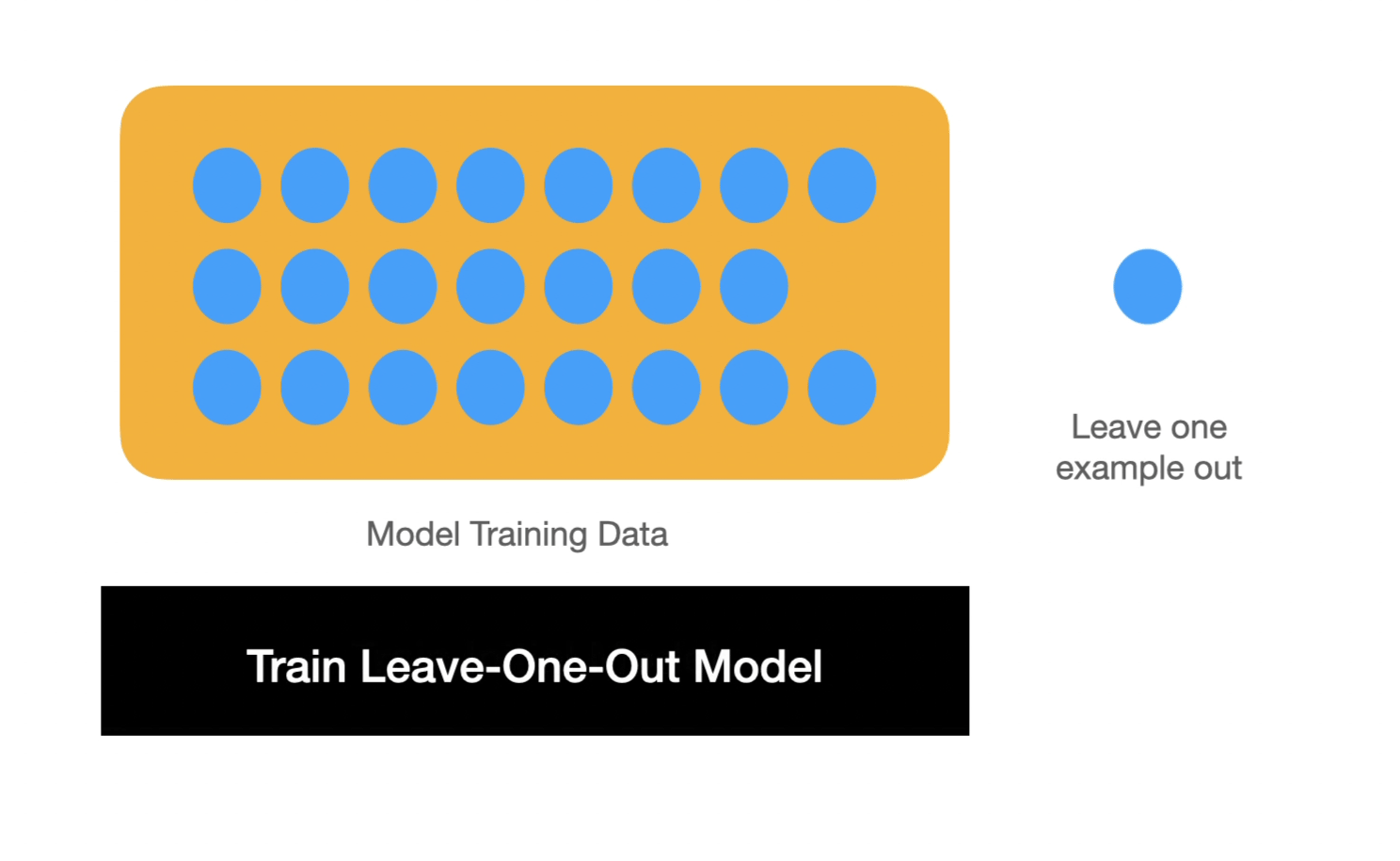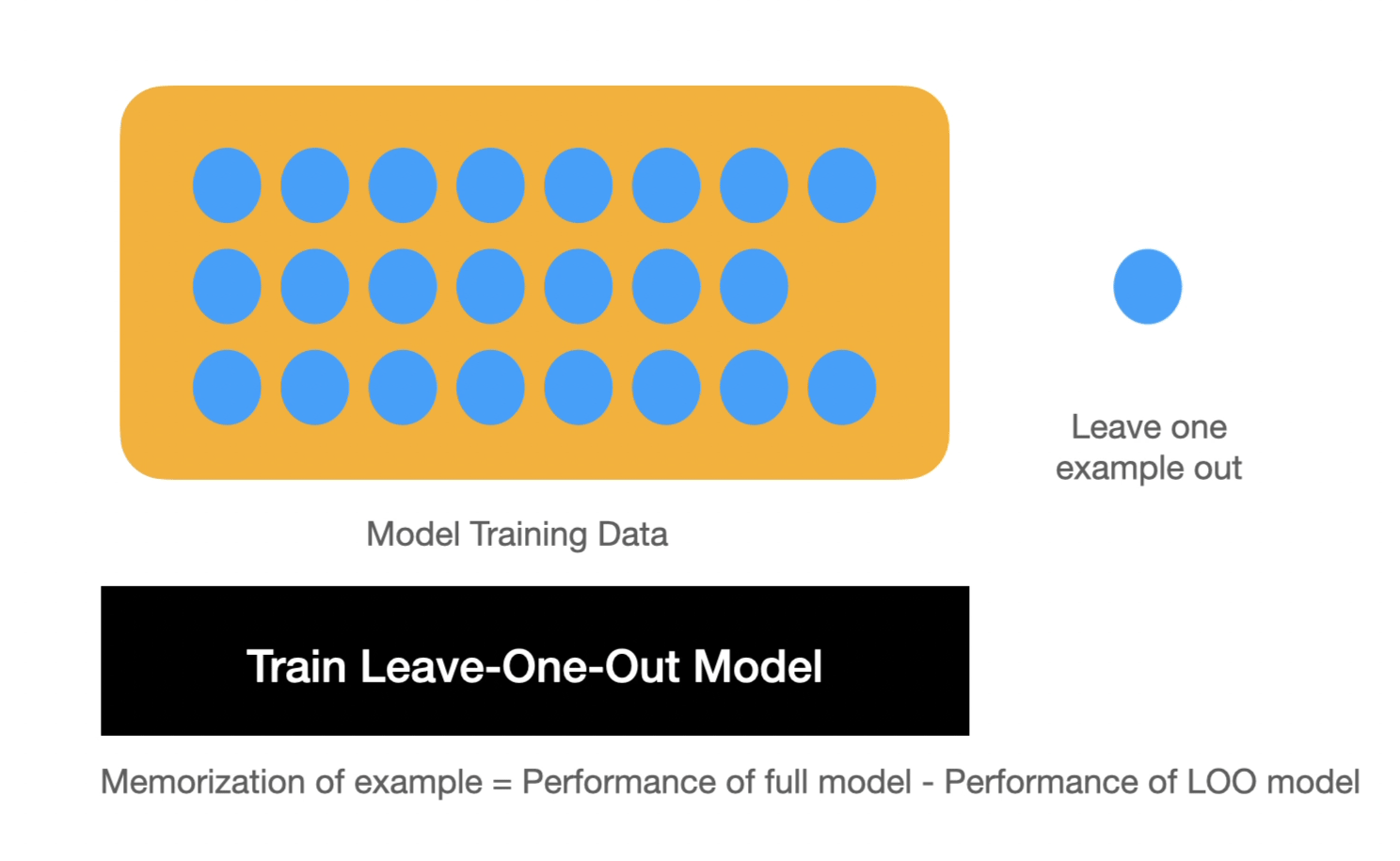
This definition combined with the toy example show that with a long-tail distribution, the optimal model performance is reached if some examples are memorized. The significant contribution of the paper presents a lower bound for model accuracy if a particular example or set of examples are not memorized. Because these are novel examples, the model must memorize them even if they are only shown once in the dataset in order to achieve higher accuracy.
 Feldman's Proof of a lower bounds
Feldman's Proof of a lower bounds
This simplification of Feldman's equation1 seems somewhat obvious -- of course the error is the optimal model plus some sort of representation of the things the model didn't learn properly. But let's summarize the impact of Feldman's normalized penalty.
Feldman was able to use typical probability theory to formulate the penalty based on properties of the population and their distribution. Remember the long-tail? His formulation creates a lower bound on what rare examples cost the model. The more rare an example, the more costly it is to the training process when the process tries to reduce error. In addition, those rare examples, or sets of rare examples are extremely costly to not learn if they will show up in the test dataset.
To put it another way, the model's error is relative to the size of a given class in the dataset and whether that class is infrequent within the overall population. As you remember from the uncommon photos of buses (odd angles, only parts of the bus), this also applies to infrequent examples of more common classes.
Based on the estimated distribution for long-tail data, the singleton examples (examples that only occur once) make up approximately 17% of the data. An algorithm that does not memorize these singleton examples will be suboptimal by approximately 7% in accuracy (maximum accuracy is then 93% if singleton's are not memorized).
Feldman's article focused on proving this mathematically; but does this happen in real machine learning or only in theory? This research spawned deeper investigations into the memorization problem with exciting results.
What color is a peacock?
Did you know there are peacocks that are completely black and white? I didn't! And neither did researcher Chiyuan Zhang who worked alongside Feldman to study the deep learning memorization phenomenon. Their work attempted to find the novel examples that a model had memorized.
Feldman and Zhang's work uncovered high influence pairs, where a "leave one out"-inspired training routine demonstrated the impact of novel examples on the model. Here are a few high influence pair examples from the paper:
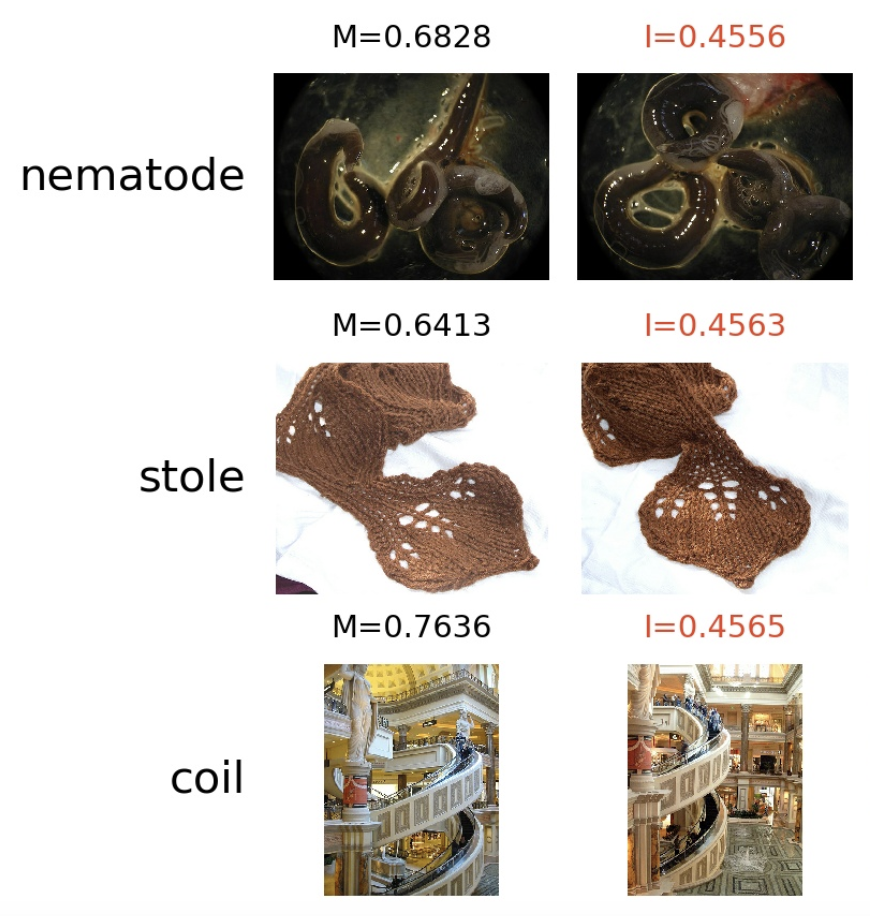
Some of these examples probably remind you of the data collection discussion from this series because some of the photos are literally from the same photo shoot. When the same photos appear in the training and testing datasets, the model's test performance will increase if it predicts those correctly. You can explore more high-influence pairs on the paper's site.
To find these high influence pairs, the researchers needed to find a way to "leave one out" and measure the impact on the model performance. Because of the high costs of training large deep learning models, they didn't leave "just one" example out and retrain. Instead, they batched the initial dataset and experimented with leaving out sets of images. They then compared the models that had seen different sets of images on the same evaluation data.
This allowed them to compare the model performance between models that had processed rare examples with other models trained the same way but without those examples. In doing so, they found the "high influence" pairs. If one of these pairs were included in the training data, the model performed much better on the test dataset example.
They also show that the influence of an image is related to the long-tail. More uncommon classes and uncommon images of that class were memorized than common ones, hence Zhang's discovery of black and white peacocks.2 They also found that about 30% of examples have some level of memorization, or a significant "influence" on the model's performance for given test points. In their experiments, they demonstrated a 2.5-3.2% performance boost that came from memorization, which supports Feldman's initial theory that optimal performance on a long-tail results in partial memorization.
These novel examples were also discovered separately by other researchers working on extracting training data from large deep learning models. Let's investigate Carlini et al.'s work on diffusion models.
And other types of deep learning models...
Carlini et al. extracted memorized examples from diffusion models3 with great success. For a quick primer on diffusion models, they are deep learning models that produce much of today's generative text-to-image models, like DALL-E or Flux. These models have a specific architecture which uses an initial "random" sampling to create a base image. This random start is processed with denoising techniques to create a visual representation that matches a particular text input. So, when you type in "a unicorn jumping over the moon", there is an approximation of what those vectors represent together based on the training data, and the model is optimized to try to extract the closest representation of that text.
 Example Stable Diffusion Steps: From noise to photorealism
Example Stable Diffusion Steps: From noise to photorealism
To test whether training data could be extracted from diffusion models, the researchers trained a large scale diffusion model on the original dataset that the Stable Diffusion team used. Then, they used prompts from the training data to test extraction.
One successful extraction is the photo below, where they used the name of an author from the training dataset. The extracted image is a near match of the original.

They were able to extract more than 100 near-identical images of training data examples like this one. More than half of the memorized extracted images are of a person. In running the attack against a larger diffusion model (Imagen), they were able to extract a higher rate than the smaller model, which supports prior research that model size also impacts memorization. They also found that more accurate models, measured by model performance metrics, memorize more data. In running further experiments, they show that by building their own diffusion model from scratch, they are able to extract 2.5% of the training data.
Later in the paper, they perform a new and different type of extraction attack, which they name an "inpainting" attack. Inpainting is a desired quality of many image-generating or editing models -- for example, to remove a person from the background of a photo and "fill in the blank". In their inpainting attack, they cover a significant portion of the image (>50%) and query the diffusion model to complete the picture. When performing these attacks, they were able to quickly see the difference between models trained on the image shown and models who were not trained on the image.

They were able to show with this research that a diffusion model that has processed the original image in training can reproduce it much more clearly than the diffusion model who has not. This again supports the "leave-one-out" approach that Feldman and Zhang used.
They also found that the easiest data to extract are outlier examples. These outliers have significant privacy risk compared to other populations. When performing the attacks, they were able to target outliers in a membership inference attack. This attack allowed them to determine if a particular image was in the training data or not. Here is a visual representation of their findings, where outliers were much easier to attack than common images.

This work on diffusion models highlighted that their training methods and processes are part of the problem; and again directly linked model size and accuracy to memorization.
Some models need to recall an individual, which makes them easier to attack. For example, a facial recognition model or a generative art model that needs to learn the styles of famous artists. These methods have inspired the types of attacks shown in papers today, which you will investigate to better understand memorization.
Model Inversion Attacks
It's important to point out that training data extraction is not a completely new attack vector and that memorization isn't either. In a paper published in 2016 by Tramér et al. (also a co-author on the diffusion paper), they designed an attack called a model inversion attack, which allows an attacker with model access to extract information from the model. The most powerful version of the attack required direct access to the model or a model trained locally that mimicked the model -- obtained via "model stealing attacks" or by training a simpler model that mimics the real model.
To perform a model inversion attack, an example of similar data is first generated. In the paper they use a facial recognition model to extract a copy of a person's face, which in this case must be memorized by the model to function correctly. They start with a base image of a face -- choosing one without significant markers (like glasses, beard, etc.).
Then, the gradient weights and activations of the local model are observed based on that input, and a loss optimizer is applied, just like you learned in training the model and evaluating the loss function. Only this time, the loss optimizer isn't trying to improve the model by training it -- it's being used to reverse engineer how to change the input in order to make it closer to the target. In this case, you want to update the image to more closely match the person's face. By doing this iteratively, you develop an image that looks like a fuzzy version of the training dataset target example.
 Model inversion attack on a facial recognition model: the training image is on the right and the extracted image is on the left
Model inversion attack on a facial recognition model: the training image is on the right and the extracted image is on the left
This shows that there are several other cases where deep learning requires memorization, and the way that deep learning models are trained can be used to extract data from them.
The funny thing is that this attack process is quite similar to how diffusion models work internally in their generative steps, making it highly susceptible to both memorization and exploits in revealing the original data. In case you missed it, the "Paragraphica" camera project was able to reproduce almost exact copies of street images that mirrored reality due to the high tendency for diffusion models to memorize their training data and repeat it when given an input query contained in the training data.
And it happens with text too...
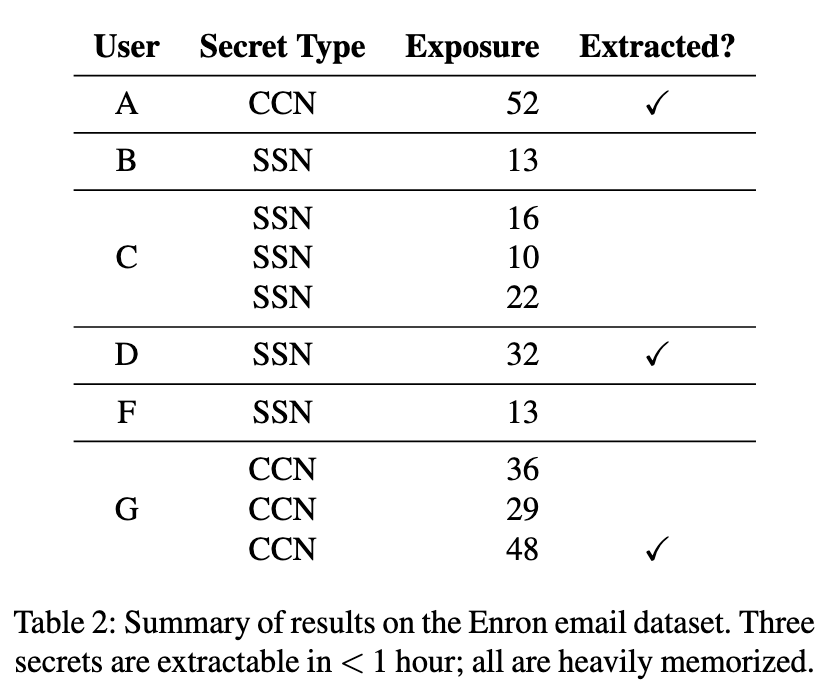
Although it's easier to demonstrate visually with images, the memorization of outliers and novel examples also occurs with text, proven in 2018 by Carlini et al's4 paper The Secret Sharer. In this paper, they were able to train a large language model using text from the Enron emails (another example of a commonly used dataset collected without direct consent). They were able to successfully extract email addresses, social security numbers and credit card numbers that appeared in the emails by crafting targeted prompts and exploiting the models tendency to memorize rarely seen data.
How did they do it? They trained a then common natural language processing (NLP) deep learning architecture (called an LSTM, another sequence-based deep learning model) with the Enron data. They trained it to predict next character tokens (which you might remember from the tokenization article). A character-level tokenization model predicts the next character given the preceding characters. The model was quite small compared to today's model sizes, with only 2 layers and likely under 5,000 parameters (it wasn't explicitly listed, this is an inference based on the numbers they posted).
Given prompts such as "My social security number is...", they used the sequence-based model to figure out the most likely continuation. Via their generation algorithm they calculate an "exposure score" -- a metric which measures the memorization of a particular sequence. Even with this small model and relatively small dataset, they were able to successfully extract several sequences, and prove a relatively high exposure (think partial memorization) for the sequences they couldn't entirely extract.
In a later investigation of the same phenomenon, many of the same authors looked at large language models, both open weight models like LLAMA and closed models like ChatGPT to extract sensitive data. They were able to do so using a few different attack vectors:
- Say "poem" forever attack: In this attack, they prompted ChatGPT to say the word poem forever. Why? The researchers believe a singular word or token repeated forever triggers behavior similar to the
token. When training a model the token is repeated many times, because it appears at the end of a document, book, or other text and those texts are joined together when performing language model training. Today's models have two training steps: one called pretraining which is base language training on many texts and then another training, where chat or instruction text is used on the already trained language model. Since the chat model requires text to be in conversational form, the repetition of a single model diverges from the second training and seems to activate the base language model, which in turn spits out memorized data.

- Nasr et al. found this attack is most successful with single words rather than multiple tokens. In addition, not all single word tokens were equal in their extraction power. For example, the word (and token) "company" was more than 100x more powerful at extracting memorized data than "poem". By spending $200 on the OpenAI API, they were able to extract more than 200,000 unique memorized sequences, which included personal information, NSFW content, user identifiers, URLs, and even literature and code. Based on a statistical estimator they trained, they predict a dedicated attacker could extract much more from ChatGPT -- noting that the rate of extraction from ChatGPT-3.5 was higher than any other model they tested. This paper was published before even larger models, like ChatGPT-4 were released.
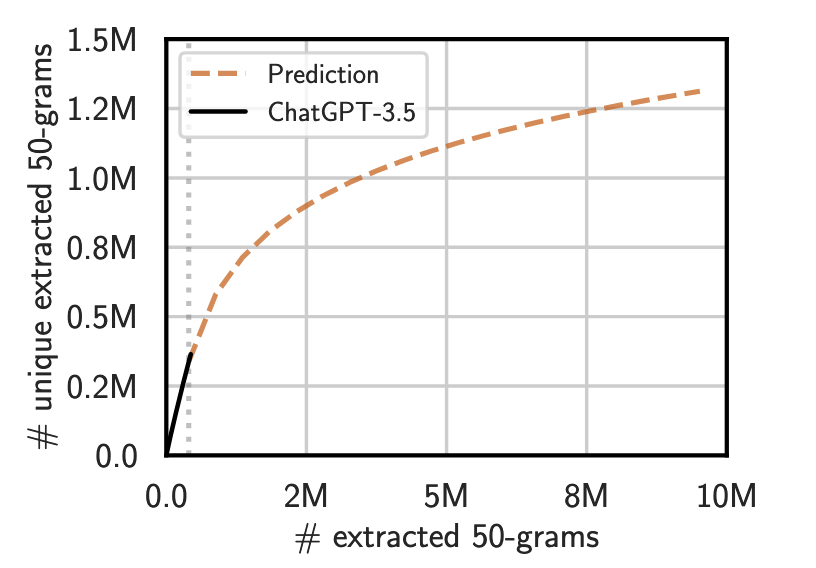
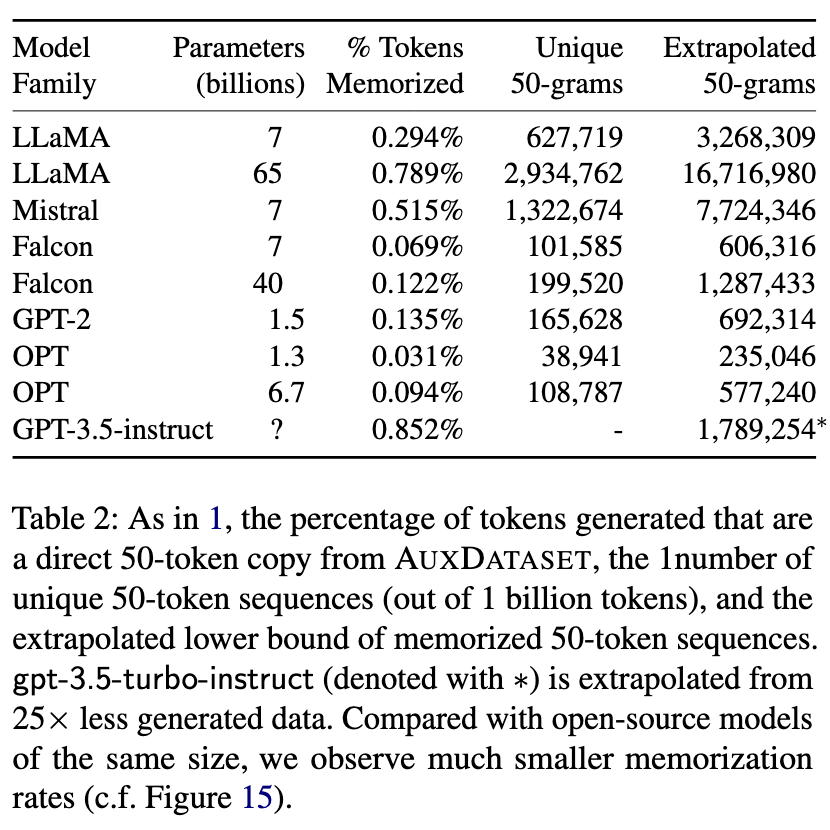
- To compare openly available models alongside the closed chat models, the authors generate longer texts and look for memorized chunks of text in the output. They compare the texts with a compilation of several popular training datasets, including The Pile and the Common Crawl Corpus. If the text has 50 tokens verbatim from the example training dataset, this is considered a successful extraction of memorized training data. For every model they successfully extract hundreds of thousands of 50-token memorized text, some which is repeated many times. To note: the training dataset of these models are unknown, and could contain all, some or only parts of the example training data that the researchers compiled. This means that these figures are lower estimates on extractability, since the actual training data would likely find better matches and provide easier extraction.
These attacks are unlikely to be the only successful ones, they are simply the most obvious ones to those who have studied the phenomenon of deep learning memorization. This research demonstrated how memorization occurs due to common text or image duplication, as explored in the previous article and now in novel cases, where the model memorizes a particular example or set of examples due to the way it is trained and optimized.
Despite attempts to remove this possibility -- such as the use of guardrails, closed models, and paid APIs -- extraction of personal data is both theoretically and practically possible. This means that personal data, copyrighted data and other sensitive data exists in the model -- saved in the model weights and biases. The data doesn't need to be repeated to be memorized. Without access to the original language models (pretraining models) and the training data used, it will be difficult to estimate the exact amount of memorized data, particularly when the companies building closed models are not incentivized or required to perform these attacks and estimates internally.
In the next article, you'll investigate how overparameterization of deep learning (aka the growth of model size) affects memorization, and how the "bigger is better" approach changed machine learning training, architectures and deployment.
I'm very open to feedback (positive, neutral or critical), questions (there are no stupid questions!) and creative re-use of this content. If you have any of those, please share it with me! This helps keep me inspired and writing. :)
Acknowledgements: I would like to thank Vicki Boykis, Damien Desfontaines and Yann Dupis for their feedback, corrections and thoughts on this series. Their input greatly contributed to improvements in my thinking and writing. Any mistakes, typos, inaccuracies or controversial opinions are my own.
-
This simplified representation of Feldman's proof is an adequate summarization for our use case; however, to learn more or read through the entire series of proofs, please read the paper or a longer study from Brown et al.. ↩
-
He mentions this find along with presenting findings of several of his publications on the topic in his MIT lecture on Quantifying and Understanding memorization in Deep Neural Networks. ↩
-
Zhang and Feldman's work on proving extraction used a traditional CNN design for computer vision (like what you learned about with AlexNet, just much larger and more modern). Diffusion models, which power much of the text-to-image generative AI, are a separate type of deep learning, where you can also extract memorized data. ↩
-
Carlini has contributed significantly to research around security in machine learning models. In case you are inspired, he wrote a blog post on Why he attacks AI. ↩